Half-precision floating-point format
In computing, half precision (sometimes called FP16) is a binary floating-point computer number format that occupies 16 bits (two bytes in modern computers) in computer memory. It is intended for storage of floating-point values in applications where higher precision is not essential, in particular computer graphics images and neural networks.
Almost all modern uses follow the IEEE 754-2008 standard, where the 16-bit base-2 format is referred to as binary16, and the exponent uses 5 bits. This can express values in the range ±65,504, with the minimum value above 1 being 1 + 1/1024.
Depending on the computer, half-precision can be over an order of magnitude faster than double precision, e.g. 550 PFLOPS for half-precision vs 37 PFLOPS for double precision on one cloud provider.[1]
| Floating-point formats |
|---|
| IEEE 754 |
| Other |
History[]
Several earlier 16-bit floating point formats have existed including that of Hitachi's HD61810 DSP[2] of 1982, Scott's WIF[3] and the 3dfx Voodoo Graphics processor.[4]
ILM was searching for an image format that could handle a wide dynamic range, but without the hard drive and memory cost of single or double precision floating point).[5] The hardware-accelerated programmable shading group led by John Airey at SGI (Silicon Graphics) invented the s10e5 data type in 1997 as part of the 'bali' design effort. This is described in a SIGGRAPH 2000 paper[6] (see section 4.3) and further documented in US patent 7518615.[7] It was popularized by its use in the open-source OpenEXR image format.
Nvidia and Microsoft defined the half datatype in the Cg language, released in early 2002, and implemented it in silicon in the GeForce FX, released in late 2002.[8] Since then support for 16-bit floating point math in graphics cards has become very common.[citation needed]
The F16C extension in 2012 allows x86 processors to convert half-precision floats to and from single-precision floats with a machine instruction.
IEEE 754 half-precision binary floating-point format: binary16[]
This section does not cite any sources. (January 2021) |
The IEEE 754 standard specifies a binary16 as having the following format:
- Sign bit: 1 bit
- Exponent width: 5 bits
- Significand precision: 11 bits (10 explicitly stored)
The format is laid out as follows:
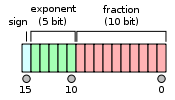
The format is assumed to have an implicit lead bit with value 1 unless the exponent field is stored with all zeros. Thus only 10 bits of the significand appear in the memory format but the total precision is 11 bits. In IEEE 754 parlance, there are 10 bits of significand, but there are 11 bits of significand precision (log10(211) ≈ 3.311 decimal digits, or 4 digits ± slightly less than 5 units in the last place).
Exponent encoding[]
This section does not cite any sources. (January 2021) |
The half-precision binary floating-point exponent is encoded using an offset-binary representation, with the zero offset being 15; also known as exponent bias in the IEEE 754 standard.
- Emin = 000012 − 011112 = −14
- Emax = 111102 − 011112 = 15
- Exponent bias = 011112 = 15
Thus, as defined by the offset binary representation, in order to get the true exponent the offset of 15 has to be subtracted from the stored exponent.
The stored exponents 000002 and 111112 are interpreted specially.
| Exponent | Significand = zero | Significand ≠ zero | Equation |
|---|---|---|---|
| 000002 | zero, −0 | subnormal numbers | (−1)signbit × 2−14 × 0.significantbits2 |
| 000012, ..., 111102 | normalized value | (−1)signbit × 2exponent−15 × 1.significantbits2 | |
| 111112 | ±infinity | NaN (quiet, signalling) | |
The minimum strictly positive (subnormal) value is 2���24 ≈ 5.96 × 10−8. The minimum positive normal value is 2−14 ≈ 6.10 × 10−5. The maximum representable value is (2−2−10) × 215 = 65504.
Half precision examples[]
This section does not cite any sources. (January 2021) |
These examples are given in bit representation of the floating-point value. This includes the sign bit, (biased) exponent, and significand.
| Binary | Hex | Value | Notes |
|---|---|---|---|
| 0 00000 0000000000 | 0000 | 0 | |
| 0 00000 0000000001 | 0001 | 2−14 × (0 + 1/1024 ) ≈ 0.000000059604645 | smallest positive subnormal number |
| 0 00000 1111111111 | 03ff | 2−14 × (0 + 1023/1024 ) ≈ 0.000060975552 | largest subnormal number |
| 0 00001 0000000000 | 0400 | 2−14 × (1 + 0/1024 ) ≈ 0.00006103515625 | smallest positive normal number |
| 0 01101 0101010101 | 3555 | 2−2 × (1 + 341/1024 ) ≈ 0.33325195 | nearest value to 1/3 |
| 0 01110 1111111111 | 3bff | 2−1 × (1 + 1023/1024 ) ≈ 0.99951172 | largest number less than one |
| 0 01111 0000000000 | 3c00 | 20 × (1 + 0/1024 ) = 1 | one |
| 0 01111 0000000001 | 3c01 | 20 × (1 + 1/1024 ) ≈ 1.00097656 | smallest number larger than one |
| 0 11110 1111111111 | 7bff | 215 × (1 + 1023/1024 ) = 65504 | largest normal number |
| 0 11111 0000000000 | 7c00 | ∞ | infinity |
| 1 00000 0000000000 | 8000 | −0 | |
| 1 10000 0000000000 | c000 | -2 | |
| 1 11111 0000000000 | fc00 | −∞ | negative infinity |
By default, 1/3 rounds down like for double precision, because of the odd number of bits in the significand. The bits beyond the rounding point are 0101... which is less than 1/2 of a unit in the last place.
Precision limitations[]
This section does not cite any sources. (January 2021) |
| Min | Max | interval |
|---|---|---|
| 0 | 2−13 | 2−24 |
| 2−13 | 2−12 | 2−23 |
| 2−12 | 2−11 | 2−22 |
| 2−11 | 2−10 | 2−21 |
| 2−10 | 2−9 | 2−20 |
| 2−9 | 2−8 | 2−19 |
| 2−8 | 2−7 | 2−18 |
| 2−7 | 2−6 | 2−17 |
| 2−6 | 2−5 | 2−16 |
| 2−5 | 2−4 | 2−15 |
| 2−4 | 1/8 | 2−14 |
| 1/8 | 1/4 | 2−13 |
| 1/4 | 1/2 | 2−12 |
| 1/2 | 1 | 2−11 |
| 1 | 2 | 2−10 |
| 2 | 4 | 2−9 |
| 4 | 8 | 2−8 |
| 8 | 16 | 2−7 |
| 16 | 32 | 2−6 |
| 32 | 64 | 2−5 |
| 64 | 128 | 2−4 |
| 128 | 256 | 1/8 |
| 256 | 512 | 1/4 |
| 512 | 1024 | 1/2 |
| 1024 | 2048 | 1 |
| 2048 | 4096 | 2 |
| 4096 | 8192 | 4 |
| 8192 | 16384 | 8 |
| 16384 | 32768 | 16 |
| 32768 | 65519 | 32 |
| 65519 | ∞ | ∞ |
65519 is the largest number that will round to a finite number (65504), 65520 and larger will round to infinity. This is for round-to-even, other rounding strategies will change this cutoff.
ARM alternative half-precision[]
ARM processors support (via a floating point control register bit) an "alternative half-precision" format, which does away with the special case for an exponent value of 31 (111112).[9] It is almost identical to the IEEE format, but there is no encoding for infinity or NaNs; instead, an exponent of 31 encodes normalized numbers in the range 65536 to 131008.
Uses[]
This format is used in several computer graphics environments to store pixels, including MATLAB, OpenEXR, JPEG XR, GIMP, OpenGL, Cg, Direct3D, and D3DX. The advantage over 8-bit or 16-bit integers is that the increased dynamic range allows for more detail to be preserved in highlights and shadows for images, and the linear representation of intensity making calculations easier. The advantage over 32-bit single-precision floating point is that it requires half the storage and bandwidth (at the expense of precision and range).[5]
Hardware and software for machine learning or neural networks tend to use half precision: such applications usually do a large amount of calculation, but don't require a high level of precision.
On older computers that access 8 or 16 bits at a time (most modern computers access 32 or 64 bits at a time), half precision arithmetic is faster than single precision, and substantially faster than double precision. On systems with instructions that can handle multiple floating point numbers with in one instruction, half-precision often offers a higher average throughput.[10]
See also[]
- bfloat16 floating-point format: Alternative 16-bit floating-point format with 8 bits of exponent and 7 bits of mantissa
- IEEE 754: IEEE standard for floating-point arithmetic (IEEE 754)
- ISO/IEC 10967, Language Independent Arithmetic
- Primitive data type
- RGBE image format
References[]
- ^ "About ABCI - About ABCI | ABCI". abci.ai. Retrieved 2019-10-06.
- ^ "hitachi :: dataBooks :: HD61810 Digital Signal Processor Users Manual". Archive.org. Retrieved 2017-07-14.
- ^ Scott, Thomas J. (March 1991). "Mathematics and Computer Science at Odds over Real Numbers". SIGCSE '91 Proceedings of the Twenty-second SIGCSE Technical Symposium on Computer Science Education. 23 (1): 130–139. doi:10.1145/107004.107029. ISBN 0897913779. S2CID 16648394.
- ^ "/home/usr/bk/glide/docs2.3.1/GLIDEPGM.DOC". Gamers.org. Retrieved 2017-07-14.
- ^ a b "OpenEXR". OpenEXR. Retrieved 2017-07-14.
- ^ Mark S. Peercy; Marc Olano; John Airey; P. Jeffrey Ungar. "Interactive Multi-Pass Programmable Shading" (PDF). People.csail.mit.edu. Retrieved 2017-07-14.
- ^ "Patent US7518615 - Display system having floating point rasterization and floating point ... - Google Patents". Google.com. Retrieved 2017-07-14.
- ^ "vs_2_sw". Cg 3.1 Toolkit Documentation. Nvidia. Retrieved 17 August 2016.
- ^ "Half-precision floating-point number support". RealView Compilation Tools Compiler User Guide. 10 December 2010. Retrieved 2015-05-05.
- ^ Ho, Nhut-Minh; Wong, Weng-Fai (September 1, 2017). "Exploiting half precision arithmetic in Nvidia GPUs" (PDF). Department of Computer Science, National University of Singapore. Retrieved July 13, 2020.
Nvidia recently introduced native half precision floating point support (FP16) into their Pascal GPUs. This was mainly motivated by the possibility that this will speed up data intensive and error tolerant applications in GPUs.
Further reading[]
External links[]
This article's use of external links may not follow Wikipedia's policies or guidelines. (July 2017) |
- Minifloats (in Survey of Floating-Point Formats)
- OpenEXR site
- Half precision constants from D3DX
- OpenGL treatment of half precision
- Fast Half Float Conversions
- Analog Devices variant (four-bit exponent)
- C source code to convert between IEEE double, single, and half precision can be found here
- Java source code for half-precision floating-point conversion
- Half precision floating point for one of the extended GCC features
- Binary arithmetic
- Floating point types