Pseudo amino acid composition
This article has multiple issues. Please help or discuss these issues on the talk page. (Learn how and when to remove these template messages)
|
Pseudo amino acid composition, or PseAAC, in molecular biology, was originally introduced by Kuo-Chen Chou in 2001 to represent protein samples for improving protein subcellular localization prediction and membrane protein type prediction.[1] Like the vanilla amino acid composition (AAC) method, it characterizes the protein mainly using a matrix of amino-acid frequencies, which helps with dealing with proteins without significant sequential homology to other proteins. Compared to AAC, additional information are also included in the matrix to represent some local features, such as correlation between residues of a certain distance.[2] When dealing the cases of PseAAC, the has been often used.
Background[]
To predict the subcellular localization of proteins and other attributes based on their sequence, two kinds of models are generally used to represent protein samples: (1) the sequential model, and (2) the non-sequential model or discrete model.
The most typical sequential representation for a protein sample is its entire amino acid (AA) sequence, which can contain its most complete information. This is an obvious advantage of the sequential model. To get the desired results, the sequence-similarity-search-based tools are usually utilized to conduct the prediction.
Given a protein sequence P with amino acid residues, i.e.,


where R1 represents the 1st residue of the protein P, R2 the 2nd residue, and so forth. This is the representation of the protein under the sequential model.
However, this kind of approach fails when a query protein does not have significant homology to the known protein(s). Thus, various discrete models were proposed that do not rely on sequence-order. The simplest discrete model is using the amino acid composition (AAC) to represent protein samples. Under the AAC model, the protein P of Eq.1 can also be expressed by

where are the normalized occurrence frequencies of the 20 native amino acids in P, and T the transposing operator. The AAC of a protein is trivially derived with the protein primary structure known like given in Eq.1; it is also possible by hydrolysis without knowing the exact sequence, and such a step in fact is often a prerequisite for protein sequencing.[3]

Owing to its simplicity, the amino acid composition (AAC) model was widely used in many earlier statistical methods for predicting protein attributes. However, all the sequence-order information is lost. This is its main shortcoming.
Concept[]
To avoid completely losing the sequence-order information, the concept of PseAAC (pseudo amino acid composition) was proposed. [1] In contrast with the conventional amino acid composition (AAC) that contains 20 components with each reflecting the occurrence frequency for one of the 20 native amino acids in a protein, the PseAAC contains a set of greater than 20 discrete factors, where the first 20 represent the components of its conventional amino acid composition while the additional factors incorporate some sequence-order information via various pseudo components.
The additional factors are a series of rank-different correlation factors along a protein chain, but they can also be any combinations of other factors so long as they can reflect some sorts of sequence-order effects one way or the other. Therefore, the essence of PseAAC is that on one hand it covers the AA composition, but on the other hand it contains the information beyond the AA composition and hence can better reflect the feature of a protein sequence through a discrete model.
Meanwhile, various modes to formulate the PseAAC vector have also been developed, as summarized in a 2009 review article.[2]
Algorithm[]
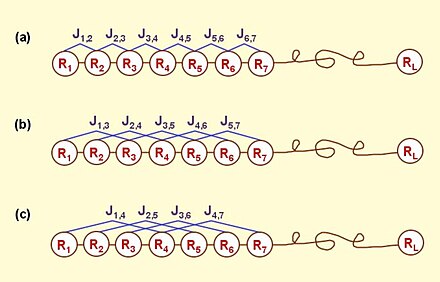

According to the PseAAC model, the protein P of Eq.1 can be formulated as

where the () components are given by

![p_{u}={\begin{cases}{\dfrac {f_{u}}{\sum _{{i=1}}^{{20}}f_{i}\,+\,w\sum _{{k=1}}^{{\lambda }}\tau _{k}}},&(1\leq u\leq 20)\\[10pt]{\dfrac {w\tau _{{u-20}}}{\sum _{{i=1}}^{{20}}f_{i}\,+\,w\sum _{{k=1}}^{{\lambda }}\tau _{k}}},&(20+1\leq u\leq 20+\lambda )\end{cases}}\qquad {\text{(4)}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9e51062076d0296d9b652c39f3ba5e010aabeb2b)
where is the weight factor, and the -th tier correlation factor that reflects the sequence order correlation between all the -th most contiguous residues as formulated by




with
![{\mathrm {J}}_{{i,i+k}}={\frac {1}{\Gamma }}\sum _{{q=1}}^{{\Gamma }}\left[\Phi _{{q}}\left({\mathrm {R}}_{{i+k}}\right)-\Phi _{{q}}\left({\mathrm {R}}_{{i}}\right)\right]^{2}\qquad {\text{(6)}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/95f4c0827bc12464e0e8ca739608a3a42081c0d2)
where is the -th function of the amino acid , and the total number of the functions considered. For example, in the original paper by Chou,[1] , and are respectively the hydrophobicity value, hydrophilicity value, and side chain mass of amino acid ; while , and the corresponding values for the amino acid . Therefore, the total number of functions considered there is . It can be seen from Eq.3 that the first 20 components, i.e. are associated with the conventional AA composition of protein, while the remaining components are the correlation factors that reflect the 1st tier, 2nd tier, …, and the -th tier sequence order correlation patterns (Figure 1). It is through these additional factors that some important sequence-order effects are incorporated.















in Eq.3 is a parameter of integer and that choosing a different integer for will lead to a dimension-different PseAA composition.[4]
Using Eq.6 is just one of the many modes for deriving the correlation factors in PseAAC or its components. The others, such as the physicochemical distance mode[5] and amphiphilic pattern mode,[6] can also be used to derive different types of PseAAC, as summarized in a 2009 review article.[2] In 2011, the formulation of PseAAC (Eq.3) was extended to a form of the general PseAAC as given by:[7]

where the subscript is an integer, and its value and the components will depend on how to extract the desired information from the amino acid sequence of P in Eq.1.


The general PseAAC can be used to reflect any desired features according to the targets of research, including those core features such as functional domain, sequential evolution, and gene ontology to improve the prediction quality for the subcellular localization of proteins.[8][9] as well as their many other important attributes.
References[]
- ^ a b c Chou KC (May 2001). "Prediction of protein cellular attributes using pseudo-amino acid composition". Proteins. 43 (3): 246–55. doi:10.1002/prot.1035. PMID 11288174. S2CID 28406797.
- ^ a b c Chou KC (2009). "Pseudo amino acid composition and its applications in bioinformatics, proteomics and system biology". Current Proteomics. 6 (4): 262–274. doi:10.2174/157016409789973707.
- ^ Michail A. Alterman; Peter Hunziker (2 December 2011). Amino Acid Analysis: Methods and Protocols. Humana Press. ISBN 978-1-61779-444-5.
- ^ Chou KC, Shen HB (November 2007). "Recent progress in protein subcellular location prediction". Anal. Biochem. 370 (1): 1–16. doi:10.1016/j.ab.2007.07.006. PMID 17698024.
- ^ Chou KC (November 2000). "Prediction of protein subcellular locations by incorporating quasi-sequence-order effect". Biochem. Biophys. Res. Commun. 278 (2): 477–83. doi:10.1006/bbrc.2000.3815. PMID 11097861.
- ^ Chou KC (January 2005). "Using amphiphilic pseudo amino acid composition to predict enzyme subfamily classes". Bioinformatics. 21 (1): 10–9. doi:10.1093/bioinformatics/bth466. PMID 15308540.
- ^ Chou KC (March 2011). "Some remarks on protein attribute prediction and pseudo amino acid composition". Journal of Theoretical Biology. 273 (1): 236–47. Bibcode:2011JThBi.273..236C. doi:10.1016/j.jtbi.2010.12.024. PMC 7125570. PMID 21168420.
- ^ Chou KC, Shen HB (2008). "Cell-PLoc: a package of Web servers for predicting subcellular localization of proteins in various organisms". Nat Protoc. 3 (2): 153–62. doi:10.1038/nprot.2007.494. PMID 18274516. S2CID 226104. Archived from the original on 2007-08-27. Retrieved 2008-03-24.
- ^ Shen HB, Chou KC (February 2008). "PseAAC: a flexible web server for generating various kinds of protein pseudo amino acid composition". Anal. Biochem. 373 (2): 386–8. doi:10.1016/j.ab.2007.10.012. PMID 17976365.
External links[]
- Amino acids
- Bioinformatics algorithms