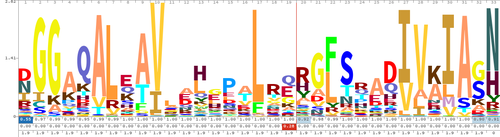
Sequence logo

In bioinformatics, a sequence logo is a graphical representation of the sequence conservation of nucleotides (in a strand of DNA/RNA) or amino acids (in protein sequences).[1] A sequence logo is created from a collection of aligned sequences and depicts the consensus sequence and diversity of the sequences. Sequence logos are frequently used to depict sequence characteristics such as protein-binding sites in DNA or functional units in proteins.
Overview[]
A sequence logo consists of a stack of letters at each position. The relative sizes of the letters indicate their frequency in the sequences. The total height of the letters depicts the information content of the position, in bits.
Logo creation[]
To create sequence logos, related DNA, RNA or protein sequences, or DNA sequences that have common conserved binding sites, are aligned so that the most conserved parts create good alignments. A sequence logo can then be created from the conserved multiple sequence alignment. The sequence logo will show how well residues are conserved at each position: the higher the number of residues, the higher the letters will be, because the better the conservation is at that position. Different residues at the same position are scaled according to their frequency. The height of the entire stack of residues is the information measured in bits. Sequence logos can be used to represent conserved DNA binding sites, where transcription factors bind.
The information content (y-axis) of position is given by:[2]

- for amino acids,
- for nucleic acids,


where is the uncertainty (sometimes called the Shannon entropy) of position


Here, is the relative frequency of base or amino acid at position , and [clarification needed] is the small-sample correction for an alignment of letters. The height of letter in column is given by





The approximation for the small-sample correction, , is given by:

where is 4 for nucleotides, 20 for amino acids, and is the number of sequences in the alignment.

Consensus logo[]
A consensus logo is a simplified variation of a sequence logo that can be embedded in text format. Like a sequence logo, a consensus logo is created from a collection of aligned protein or DNA/RNA sequences and conveys information about the conservation of each position of a sequence motif or sequence alignment[1][3] . However, a consensus logo displays only conservation information, and not explicitly the frequency information of each nucleotide or amino acid at each position. Instead of a stack made of several characters, denoting the relative frequency of each character, the consensus logo depicts the degree of conservation of each position using the height of the consensus character at that position.
Advantages and drawbacks[]
The main, and obvious, advantage of consensus logos over sequence logos is their ability to be embedded as text in any Rich Text Format supporting editor/viewer and, therefore, in scientific manuscripts. As described above, the consensus logo is a cross between sequence logos and consensus sequences. As a result, compared to a sequence logo, the consensus logo omits information (the relative contribution of each character to the conservation of that position in the motif/alignment). Hence, a sequence logo should be used preferentially whenever possible. That being said, the need to include graphic figures in order to display sequence logos has perpetuated the use of consensus sequences in scientific manuscripts, even though they fail to convey information on both conservation and frequency.[4] Consensus logos represent therefore an improvement over consensus sequences whenever motif/alignment information has to be constrained to text.
Extensions[]
Hidden Markov models (HMMs) not only consider the information content of aligned positions in an alignment, but also of insertions and deletions. In an HMM sequence logo used by Pfam, three rows are added to indicate the frequencies of occupancy (presence) and insertion, as well as the expected insertion length.[5]
See also[]
- Sequence motif
- Position-specific scoring matrix
- DNA binding site
References[]
- ^ a b Schneider TD; Stephens RM (1990). "Sequence Logos: A New Way to Display Consensus Sequences". Nucleic Acids Res. 18 (20): 6097–6100. doi:10.1093/nar/18.20.6097. PMC 332411. PMID 2172928.
- ^ Schneider TD; Stormo GD (1986). "Information content of binding sites on nucleotide sequences" (PDF). Journal of Molecular Biology. 188 (3): 415–431. doi:10.1016/0022-2836(86)90165-8. PMID 3525846.
- ^ Anzaldi LJ; Muñoz-Fernández D; Erill I. (2012). "BioWord: a sequence manipulation suite for Microsoft Word". BMC Bioinformatics. 13 (124): 124. doi:10.1186/1471-2105-13-124. PMC 3546851. PMID 22676326.
- ^ Schneider TD (2002). "Consensus Sequence Zen". Appl Bioinform. 1 (3): 111–119. PMC 1852464. PMID 15130839.
- ^ Wheeler, Travis J; Clements, Jody; Finn, Robert D (13 January 2014). "Skylign: a tool for creating informative, interactive logos representing sequence alignments and profile hidden Markov models". BMC Bioinformatics. 15 (1): 7. doi:10.1186/1471-2105-15-7. PMC 3893531. PMID 24410852.
External links[]
- How to read sequence logos.
- Recommendations for Making Sequence Logos.
- Erill, I., "A gentle introduction to information content in transcription factor binding sites", Eprint
- What is (in) a sequence logo?
- Bioinformatics
- Statistical charts and diagrams