Tunstall coding
In computer science and information theory, Tunstall coding is a form of entropy coding used for lossless data compression.
History[]
Tunstall coding was the subject of Brian Parker Tunstall's PhD thesis in 1967, while at Georgia Institute of Technology. The subject of that thesis was "Synthesis of noiseless compression codes" [1]
Its design is a precursor to Lempel–Ziv.
Properties[]
Unlike variable-length codes, which include Huffman and Lempel–Ziv coding, Tunstall coding is a code which maps source symbols to a fixed number of bits.[2]
Both Tunstall codes and Lempel–Ziv codes represent variable-length words by fixed-length codes.[3]
Unlike typical set encoding, Tunstall coding parses a stochastic source with codewords of variable length.
It can be shown[4] that, for a large enough dictionary, the number of bits per source letter can be arbitrarily close to , the entropy of the source.

Algorithm[]
The algorithm requires as input an input alphabet , along with a distribution of probabilities for each word input. It also requires an arbitrary constant , which is an upper bound to the size of the dictionary that it will compute. The dictionary in question, , is constructed as a tree of probabilities, in which each edge is associated to a letter from the input alphabet. The algorithm goes like this:



D := tree of leaves, one for each letter in . While : Convert most probable leaf to tree with leaves.


Example[]
This article may require cleanup to meet Wikipedia's quality standards. The specific problem is: wrong probabilities. (August 2014) |
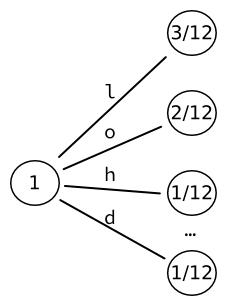
Let's imagine that we wish to encode the string "hello, world". Let's further assume (somewhat unrealistically) that the input alphabet contains only characters from the string "hello, world" — that is, 'h', 'e', 'l', ',', ' ', 'w', 'o', 'r', 'd'. We can therefore compute the probability of each character based on its statistical appearance in the input string. For instance, the letter L appears thrice in a string of 12 characters: its probability is .

We initialize the tree, starting with a tree of leaves. Each word is therefore directly associated to a letter of the alphabet. The 9 words that we thus obtain can be encoded into a fixed-sized output of bits.


We then take the leaf of highest probability (here, ), and convert it to yet another tree of leaves, one for each character. We re-compute the probabilities of those leaves. For instance, the sequence of two letters L happens once. Given that there are three occurrences of letters followed by an L, the resulting probability is .


We obtain 17 words, which can each be encoded into a fixed-sized output of bits.

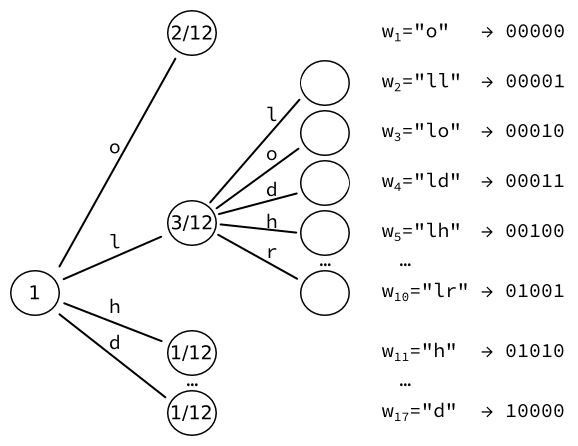
Note that we could iterate further, increasing the number of words by every time.

Limitations[]
Tunstall coding requires the algorithm to know, prior to the parsing operation, what the distribution of probabilities for each letter of the alphabet is. This issue is shared with Huffman coding.
Its requiring a fixed-length block output makes it lesser than Lempel–Ziv, which has a similar dictionary-based design, but with a variable-sized block output.[clarification needed]
References[]
- ^ Tunstall, Brian Parker (September 1967). Synthesis of noiseless compression codes. Georgia Institute of Technology.
- ^ http://www.rle.mit.edu/rgallager/documents/notes1.pdf, Study of Tunstall's algorithm at MIT
- ^ "Variable to fixed length adaptive source coding - Lempel-Ziv coding". [1] [2]
- ^ [3], Study of Tunstall's algorithm from EPFL's Information Theory department
| Wikimedia Commons has media related to Tunstall coding. |
Data compression methods | |||||||
|---|---|---|---|---|---|---|---|
| Lossless |
| ||||||
| Lossy |
| ||||||
| Audio |
| ||||||
| Image |
| ||||||
| Video |
| ||||||
| Theory | |||||||
| |||||||
- Data compression
- Lossless compression algorithms