Disaster recovery
Disaster Recovery involves a set of policies, tools and procedures to enable the recovery or continuation of vital technology infrastructure and systems following a natural or human-induced disaster. Disaster recovery focuses on the IT or technology systems supporting critical business functions,[1] as opposed to business continuity, which involves keeping all essential aspects of a business functioning despite significant disruptive events. Disaster recovery can therefore be considered a subset of business continuity.[2][3] Disaster Recovery assumes that the primary site is not recoverable (at least for some time) and represents a process of restoring data and services to a secondary survived site, which is opposite to the process of restoring back to its original place.
IT Service Continuity[]
IT Service Continuity[4][5] (ITSC) is a subset of business continuity planning (BCP)[6] and encompasses IT disaster recovery planning and wider IT resilience planning. It also incorporates those elements of IT infrastructure and services which relate to communications such as (voice) telephony and data communications.
The ITSC Plan reflects Recovery Point Objective (RPO - recent transactions) and Recovery Time Objective (RTO - time intervals).
Principles of Backup sites[]
Planning includes arranging for backup sites, be they hot, warm, cold, or standby sites, with hardware as needed for continuity.
In 2008 the British Standards Institution launched a specific standard connected and supporting the Business Continuity Standard BS 25999 titled BS25777 specifically to align computer continuity with business continuity. This was withdrawn following the publication in March 2011 of ISO/IEC 27031 - Security techniques — Guidelines for information and communication technology readiness for business continuity.
ITIL has defined some of these terms.[7]
Recovery Time Objective[]
The Recovery Time Objective (RTO)[8][9] is the targeted duration of time and a service level within which a business process must be restored after a disaster (or disruption) in order to avoid unacceptable consequences associated with a break in business continuity.[10]
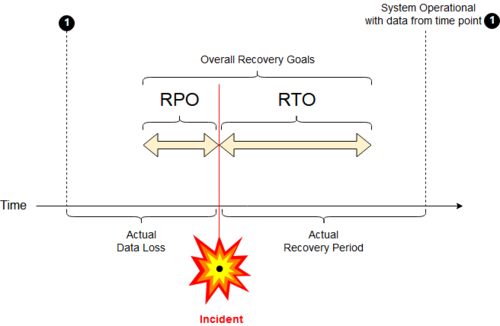
In accepted business continuity planning methodology, the RTO is established during the Business Impact Analysis (BIA) by the owner of a process, including identifying options time frames for alternate or manual workarounds.
In a good deal of the literature on this subject, RTO is spoken of as a complement of Recovery Point Objective (RPO), with the two metrics describing the limits of acceptable or "tolerable" ITSC performance in terms of time lost (RTO) from normal business process functioning, and in terms of data lost or not backed up during that period of time (RPO) respectively.[10][11]
Recovery Time Actual[]
A Forbes overview[8] noted that it is Recovery Time Actual (RTA) which is "the critical metric for business continuity and disaster recovery."
RTA is established during exercises or actual events. The business continuity group times rehearsals (or actuals) and makes needed refinements.[8][12]
Recovery Point Objective[]
A Recovery Point Objective (RPO) is defined by business continuity planning. It is the maximum targeted period in which data (transactions) might be lost from an IT service due to a major incident.[10]
If RPO is measured in minutes (or even a few hours), then in practice, off-site mirrored backups must be continuously maintained; a daily off-site backup on tape will not suffice.[13]
Relationship to Recovery Time Objective[]
Recovery that is not instantaneous will restore data/transactions over a period of time and do so without incurring significant risks or significant losses.[10]
RPO measures the maximum time period in which recent data might have been permanently lost in the event of a major incident and is not a direct measure of the quantity of such loss. For instance, if the BC plan is "restore up to last available backup", then the RPO is the maximum interval between such backup that has been safely vaulted off-site.
Business impact analysis is used to determine RPO for each service and RPO is not determined by the existent backup regime. When any level of preparation of off-site data is required, the period during which data might be lost often starts near the time of the beginning of the work to prepare backups, not the time the backups are taken off-site.[11]
Data synchronization points[]
Although a data synchronization point[14] is a point in time, the timing for performing the physical backup must be included. One approach used is to halt processing of an update queue, while a disk-to-disk copy is made. The backup[15] reflects the earlier time of that copy operation, not when the data is copied to tape or transmitted elsewhere.
How RTO and RPO values affect computer system design[]
RTO and the RPO must be balanced, taking business risk into account, along with all the other major system design criteria.[16]
RPO is tied to the times backups are sent offsite. Offsiting via synchronous copies to an offsite mirror allows for most unforeseen difficulty. Use of physical transportation for tapes (or other transportable media) comfortably covers some backup needs at a relatively low cost. Recovery can be enacted at a predetermined site. Shared offsite space and hardware completes the package needed.[17]
For high volumes of high value transaction data, the hardware can be split across two or more sites; splitting across geographic areas adds resiliency.
History[]
Planning for disaster recovery and information technology (IT) developed in the mid- to late 1970s as computer center managers began to recognize the dependence of their organizations on their computer systems.
At that time, most systems were batch-oriented mainframes. Another offsite mainframe could be loaded from backup tapes pending recovery of the primary site; downtime was relatively less critical.
The disaster recovery industry[18][19] developed to provide backup computer centers. One of the earliest such centers was located in Sri Lanka (Sungard Availability Services, 1978).[20][21]
During the 1980s and 90s, as internal corporate timesharing, online data entry and real-time processing grew, more availability of IT systems was needed.
Regulatory agencies became involved even before the rapid growth of the Internet during the 2000s; objectives of 2, 3, 4 or 5 nines (99.999%) were often mandated, and high-availability solutions for hot-site facilities were sought.[citation needed]
IT Service Continuity is essential for many organizations in the implementation of Business Continuity Management (BCM) and Information Security Management (ICM) and as part of the implementation and operation information security management as well as business continuity management as specified in ISO/IEC 27001 and ISO 22301 respectively.
The rise of cloud computing since 2010 continues that trend: nowadays, it matters even less where computing services are physically served, just so long as the network itself is sufficiently reliable (a separate issue, and less of a concern since modern networks are highly resilient by design). 'Recovery as a Service' (RaaS) is one of the security features or benefits of cloud computing being promoted by the Cloud Security Alliance.[22]
Classification of disasters[]
Disasters can be the result of three broad categories of threats and hazards. The first category is natural hazards that include acts of nature such as floods, hurricanes, tornadoes, earthquakes, and epidemics. The second category is technological hazards that include accidents or the failures of systems and structures such as pipeline explosions, transportation accidents, utility disruptions, dam failures, and accidental hazardous material releases. The third category is human-caused threats that include intentional acts such as active assailant attacks, chemical or biological attacks, cyber attacks against data or infrastructure, and sabotage. Preparedness measures for all categories and types of disasters fall into the five mission areas of prevention, protection, mitigation, response, and recovery.[23]
Importance of disaster recovery planning[]
Recent research supports the idea that implementing a more holistic pre-disaster planning approach is more cost-effective in the long run. Every $1 spent on hazard mitigation (such as a disaster recovery plan) saves society $4 in response and recovery costs.[24]
2015 disaster recovery statistics suggest that downtime lasting for one hour can cost
- small companies as much as $8,000,
- mid-size organizations $74,000, and
- large enterprises $700,000.[25]
As IT systems have become increasingly critical to the smooth operation of a company, and arguably the economy as a whole, the importance of ensuring the continued operation of those systems, and their rapid recovery, has increased. For example, of companies that had a major loss of business data, 43% never reopen and 29% close within two years. As a result, preparation for continuation or recovery of systems needs to be taken very seriously. This involves a significant investment of time and money with the aim of ensuring minimal losses in the event of a disruptive event.[26]
Control measures[]
Control measures are steps or mechanisms that can reduce or eliminate various threats for organizations. Different types of measures can be included in a disaster recovery plan (DRP).
Disaster recovery planning is a subset of a larger process known as business continuity planning and includes planning for resumption of applications, data, hardware, electronic communications (such as networking), and other IT infrastructure. A business continuity plan (BCP) includes planning for non-IT related aspects such as key personnel, facilities, crisis communication, and reputation protection and should refer to the disaster recovery plan (DRP) for IT-related infrastructure recovery/continuity.
IT disaster recovery control measures can be classified into the following three types:
- Preventive measures – Controls aimed at preventing an event from occurring.
- Detective measures – Controls aimed at detecting or discovering unwanted events.
- Corrective measures – Controls aimed at correcting or restoring the system after a disaster or an event.
Good disaster recovery plan measures dictate that these three types of controls be documented and exercised regularly using so-called "DR tests".
Strategies[]
Prior to selecting a disaster recovery strategy, a disaster recovery planner first refers to their organization's business continuity plan, which should indicate the key metrics of Recovery Point Objective and Recovery Time Objective.[27] Metrics for business processes are then mapped to their systems and infrastructure.[28]
Failure to properly plan can extend the disaster's impact.[29] Once metrics have been mapped, the organization reviews the IT budget; RTO and RPO metrics must fit with the available budget. A cost-benefit analysis often dictates which disaster recovery measures are implemented.
Adding cloud-based backup to the benefits of local and offsite tape archiving, the New York Times wrote, "adds a layer of data protection."[30]
Common strategies for data protection include:
- backups made to tape and sent off-site at regular intervals
- backups made to disk on-site and automatically copied to off-site disk, or made directly to off-site disk
- replication of data to an off-site location, which overcomes the need to restore the data (only the systems then need to be restored or synchronized), often making use of storage area network (SAN) technology
- Private Cloud solutions which replicate the management data (VMs, Templates and disks) into the storage domains which are part of the private cloud setup. These management data are configured as an xml representation called OVF (Open Virtualization Format), and can be restored once a disaster occurs.
- Hybrid Cloud solutions that replicate both on-site and to off-site data centers. These solutions provide the ability to instantly fail-over to local on-site hardware, but in the event of a physical disaster, servers can be brought up in the cloud data centers as well.
- the use of high availability systems which keep both the data and system replicated off-site, enabling continuous access to systems and data, even after a disaster (often associated with cloud storage)[31]
In many cases, an organization may elect to use an outsourced disaster recovery provider to provide a stand-by site and systems rather than using their own remote facilities, increasingly via cloud computing.
In addition to preparing for the need to recover systems, organizations also implement precautionary measures with the objective of preventing a disaster in the first place. These may include:
- local mirrors of systems and/or data and use of disk protection technology such as RAID
- surge protectors — to minimize the effect of power surges on delicate electronic equipment
- use of an uninterruptible power supply (UPS) and/or backup generator to keep systems going in the event of a power failure
- fire prevention/mitigation systems such as alarms and fire extinguishers
- anti-virus software and other security measures
Disaster Recovery as a Service (DRaaS)[]
Disaster Recovery as a Service DRaaS is an arrangement with a third party, a vendor.[32] Commonly offered by Service Providers as part of their service portfolio.
Although vendor lists have been published, disaster recovery is not a product, it's a service, even though several large hardware vendors have developed mobile/modular offerings that can be installed and made operational in very short time.

- Cisco Systems[33]
- Google (Google Modular Data Center) has developed systems that could be used for this purpose.[34][35]
- Bull (mobull)[36]
- HP (Performance Optimized Datacenter)[37]
- Huawei (Container Data Center Solution),[38]
- IBM (Portable Modular Data Center)
- Schneider-Electric (Portable Modular Data Center)
- Sun Microsystems (Sun Modular Datacenter)[39]
- SunGard Availability Services
- ZTE Corporation
See also[]
- Backup site
- Business continuity
- Business continuity planning
- Continuous data protection
- Disaster recovery plan
- Disaster response
- Emergency management
- High availability
- Information System Contingency Plan
- Real-time recovery
- Recovery Consistency Objective
- Remote backup service
- Virtual tape library
- BS 25999
References[]
- ^ Systems and Operations Continuity: Disaster Recovery. Georgetown University. University Information Services. Retrieved 3 August 2012.
- ^ Disaster Recovery and Business Continuity, version 2011. Archived January 11, 2013, at the Wayback Machine IBM. Retrieved 3 August 2012.
- ^ [1] 'What is Business Continuity Management', DRI International, 2017
- ^ M. Niemimaa; Steven Buchanan (March 2017). "Information systems continuity process". ACM.com (ACM Digital Library).
- ^ "2017 IT Service Continuity Directory" (PDF). Disaster Recovery Journal.
- ^ "Defending The Data Strata". ForbesMiddleEast.com. December 24, 2013.
- ^ "ITIL glossary and abbreviations".
- ^ Jump up to: a b c "Like The NFL Draft, Is The Clock The Enemy Of Your Recovery Time". Forbes. April 30, 2015.
- ^ "Three Reasons You Can't Meet Your Disaster Recovery Time". Forbes. October 10, 2013.
- ^ Jump up to: a b c d "Understanding RPO and RTO". DRUVA. 2008. Retrieved February 13, 2013.
- ^ Jump up to: a b "How to fit RPO and RTO into your backup and recovery plans". SearchStorage. Retrieved 2019-05-20.
- ^ "Clock... modifications
- ^ Richard May. "Finding RPO and RTO". Archived from the original on 2016-03-03.
- ^ "Data transfer and synchronization between mobile systems". May 14, 2013.
- ^ "Amendment #5 to S-1". SEC.gov.
real-time ... provide redundancy and back-up to ...
- ^ Peter H. Gregory (2011-03-03). "Setting the Maximum Tolerable Downtime -- setting recovery objectives". IT Disaster Recovery Planning For Dummies. Wiley. pp. 19–22. ISBN 978-1118050637.
- ^ William Caelli; Denis Longley (1989). Information Security for Managers. p. 177. ISBN 1349101370.
- ^ "Catastrophe? It Can't Possibly Happen Here". The New York Times. January 29, 1995.
.. patient records
- ^ "Commercial Property/Disaster Recovery". NYTimes.com. October 9, 1994.
...the disaster-recovery industry has grown to
- ^ Charlie Taylor (June 30, 2015). "US tech firm Sungard announces 50 jobs for Dublin". The Irish Times.
Sungard .. founded 1978
- ^ Cassandra Mascarenhas (November 12, 2010). "SunGard to be a vital presence in the banking industry". Wijeya Newspapers Ltd.
SunGard ... Sri Lanka’s future.
- ^ SecaaS Category 9 // BCDR Implementation Guidance CSA, retrieved 14 July 2014.
- ^ "Threat and Hazard Identification and Risk Assessment (THIRA) and Stakeholder Preparedness Review (SPR): Guide Comprehensive Preparedness Guide (CPG) 201, 3rd Edition" (PDF). US Department of Homeland Security. May 2018.
- ^ "Post-Disaster Recovery Planning Forum: How-To Guide, Prepared by Partnership for Disaster Resilience". University of Oregon's Community Service Center, (C) 2007, www.OregonShowcase.org. Retrieved October 29, 2018.
- ^ "The Importance of Disaster Recovery". Retrieved October 29, 2018.
- ^ "IT Disaster Recovery Plan". FEMA. 25 October 2012. Retrieved 11 May 2013.
- ^ "Use of the Professional Practices framework to develop,implement,maintain a business continuity program can reduce the likelihood of significant gaps". DRI International. 2021-08-16. Retrieved 2021-09-02.
- ^ Gregory, Peter. CISA Certified Information Systems Auditor All-in-One Exam Guide, 2009. ISBN 978-0-07-148755-9. Page 480.
- ^ "Five Mistakes That Can Kill a Disaster Recovery Plan". Dell.com. Archived from the original on 2013-01-16. Retrieved 2012-06-22.
- ^ J. D. Biersdorfer (April 5, 2018). "Monitoring the Health of a Backup Drive". The New York Times.
- ^ Brandon, John (23 June 2011). "How to Use the Cloud as a Disaster Recovery Strategy". Inc. Retrieved 11 May 2013.
- ^ "Disaster Recovery as a Service (DRaaS)".
- ^ "Info and video about Cisco's solution". Datacentreknowledge. May 15, 2007. Archived from the original on 2008-05-19. Retrieved 2008-05-11.
- ^ Kraemer, Brian (June 11, 2008). "IBM's Project Big Green Takes Second Step". ChannelWeb. Archived from the original on 2008-06-11. Retrieved 2008-05-11.
- ^ "Modular/Container Data Centers Procurement Guide: Optimizing for Energy Efficiency and Quick Deployment" (PDF). Archived from the original (PDF) on 2013-05-31. Retrieved 2013-08-30.
- ^ Kidger, Daniel. "Mobull Plug and Boot Datacenter". Bull. Archived from the original on 2010-11-19. Retrieved 2011-05-24.
- ^ "HP Performance Optimized Datacenter (POD) 20c and 40c - Product Overview". H18004.www1.hp.com. Archived from the original on 2015-01-22. Retrieved 2013-08-30.
- ^ "Huawei's Container Data Center Solution". Huawei. Retrieved 2014-05-17.
- ^ "Technical specs of Sun's Blackbox". Archived from the original on 2008-05-13. Retrieved 2008-05-11.
Further reading[]
- Barnes, James (2001). A guide to business continuity planning. Chichester, NY: John Wiley. ISBN 9780470845431. OCLC 50321216.
- Bell, Judy Kay (2000). Disaster survival planning : a practical guide for businesses. Port Hueneme, CA, US: Disaster Survival Planning. ISBN 9780963058027. OCLC 45755917.
- Fulmer, Kenneth (2015). Business Continuity Planning : a Step-by-Step Guide With Planning Forms. Brookfield, CT: Rothstein Associates, Inc. ISBN 9781931332804. OCLC 712628907, 905750518, 1127407034.
- DiMattia, Susan S (2001). "Planning for Continuity". Library Journal. 126 (19): 32–34. ISSN 0363-0277. OCLC 425551440.
- Harney, John (July–August 2004). "Business Continuity and Disaster Recovery: Back Up Or Shut Down". AIIM E-DOC Magazine. ISSN 1544-3647. OCLC 1058059544. Archived from the original on 2008-02-04.
- "ISO 22301:2019(en), Security and resilience — Business continuity management systems — Requirements". ISO.
- "ISO/IEC 27001:2013(en) Information technology — Security techniques — Information security management systems — Requirements". ISO.
- "ISO/IEC 27002:2013(en) Information technology — Security techniques — Code of practice for information security controls". ISO.
External links[]
- "Glossary of terms for Business Continuity, Disaster Recovery and related data mirroring & z/OS storage technology solutions". recoveryspecialties.com. Archived from the original on 2020-11-14. Retrieved 2021-09-02.
- "IT Disaster Recovery Plan". Ready.gov. Retrieved 2021-09-02.
- "RPO (Recovery Point Objective) Explained". IBM. 2019-08-08. Retrieved 2021-09-02.
| Authority control |
|---|
- Disaster recovery
- Backup
- Business continuity
- Data management
- Information technology management
- IT risk management