Multiplication algorithm
A multiplication algorithm is an algorithm (or method) to multiply two numbers. Depending on the size of the numbers, different algorithms are used. Efficient multiplication algorithms have existed since the advent of the decimal system.
Grid method[]
The grid method (or box method) is an introductory method for multiple-digit multiplication that is often taught to pupils at primary school or elementary school. It has been a standard part of the national primary school mathematics curriculum in England and Wales since the late 1990s.[1]
Both factors are broken up ("partitioned") into their hundreds, tens and units parts, and the products of the parts are then calculated explicitly in a relatively simple multiplication-only stage, before these contributions are then totalled to give the final answer in a separate addition stage.
The calculation 34 × 13, for example, could be computed using the grid:
300 40 90 + 12 ———— 442
| × | 30 | 4 |
|---|---|---|
| 10 | 300 | 40 |
| 3 | 90 | 12 |
followed by addition to obtain 442, either in a single sum (see right), or through forming the row-by-row totals (300 + 40) + (90 + 12) = 340 + 102 = 442.
This calculation approach (though not necessarily with the explicit grid arrangement) is also known as the partial products algorithm. Its essence is the calculation of the simple multiplications separately, with all addition being left to the final gathering-up stage.
The grid method can in principle be applied to factors of any size, although the number of sub-products becomes cumbersome as the number of digits increases. Nevertheless, it is seen as a usefully explicit method to introduce the idea of multiple-digit multiplications; and, in an age when most multiplication calculations are done using a calculator or a spreadsheet, it may in practice be the only multiplication algorithm that some students will ever need.
Long multiplication[]
If a positional numeral system is used, a natural way of multiplying numbers is taught in schools as long multiplication, sometimes called grade-school multiplication, sometimes called Standard Algorithm: multiply the multiplicand by each digit of the multiplier and then add up all the properly shifted results. It requires memorization of the multiplication table for single digits.
This is the usual algorithm for multiplying larger numbers by hand in base 10. Computers initially used a very similar shift and add algorithm in base 2, but modern processors have optimized circuitry for fast multiplications using more efficient algorithms, at the price of a more complex hardware realization. A person doing long multiplication on paper will write down all the products and then add them together; an abacus-user will sum the products as soon as each one is computed.
Example[]
This example uses long multiplication to multiply 23,958,233 (multiplicand) by 5,830 (multiplier) and arrives at 139,676,498,390 for the result (product).
23958233
× 5830
———————————————
00000000 ( = 23,958,233 × 0)
71874699 ( = 23,958,233 × 30)
191665864 ( = 23,958,233 × 800)
+ 119791165 ( = 23,958,233 × 5,000)
———————————————
139676498390 ( = 139,676,498,390 )
Below pseudocode describes the process of above multiplication. It keeps only one row to maintain the sum which finally becomes the result. Note that the '+=' operator is used to denote sum to existing value and store operation (akin to languages such as Java and C) for compactness.
multiply(a[1..p], b[1..q], base) // Operands containing rightmost digits at index 1
product = [1..p+q] // Allocate space for result
for b_i = 1 to q // for all digits in b
carry = 0
for a_i = 1 to p // for all digits in a
product[a_i + b_i - 1] += carry + a[a_i] * b[b_i]
carry = product[a_i + b_i - 1] / base
product[a_i + b_i - 1] = product[a_i + b_i - 1] mod base
product[b_i + p] = carry // last digit comes from final carry
return product
Optimizing space complexity[]
This section does not cite any sources. (September 2012) |
Let n be the total number of digits in the two input numbers in base D. If the result must be kept in memory then the space complexity is trivially Θ(n). However, in certain applications, the entire result need not be kept in memory and instead the digits of the result can be streamed out as they are computed (for example, to system console or file). In these scenarios, long multiplication has the advantage that it can easily be formulated as a log space algorithm; that is, an algorithm that only needs working space proportional to the logarithm of the number of digits in the input (Θ(log n)). This is the double logarithm of the numbers being multiplied themselves (log log N). Note that operands themselves still need to be kept in memory and their Θ(n) space is not considered in this analysis.
The method is based on the observation that each digit of the result can be computed from right to left with only knowing the carry from the previous step. Let ai and bi be the i-th digit of the operand, with a and b padded on the left by zeros to be length n, ri be the i-th digit of the result and ci be the carry generated for ri (i=1 is the right most digit) then

or

A simple inductive argument shows that the carry can never exceed n and the total sum for ri can never exceed D * n: the carry into the first column is zero, and for all other columns, there are at most n digits in the column, and a carry of at most n from the previous column (by the induction hypothesis). The sum is at most D * n, and the carry to the next column is at most D * n / D, or n. Thus both these values can be stored in O(log n) digits.
In pseudocode, the log-space algorithm is:
multiply(a[1..p], b[1..q], base) // Operands containing rightmost digits at index 1
tot = 0
for ri = 1 to p + q - 1 // For each digit of result
for bi = MAX(1, ri - p + 1) to MIN(ri, q) // Digits from b that need to be considered
ai = ri − bi + 1 // Digits from a follow "symmetry"
tot = tot + (a[ai] * b[bi])
product[ri] = tot mod base
tot = floor(tot / base)
product[p+q] = tot mod base // Last digit of the result comes from last carry
return product
Usage in computers[]
Some chips implement long multiplication, in hardware or in microcode, for various integer and floating-point word sizes. In arbitrary-precision arithmetic, it is common to use long multiplication with the base set to 2w, where w is the number of bits in a word, for multiplying relatively small numbers.
To multiply two numbers with n digits using this method, one needs about n2 operations. More formally: using a natural size metric of number of digits, the time complexity of multiplying two n-digit numbers using long multiplication is Θ(n2).
When implemented in software, long multiplication algorithms must deal with overflow during additions, which can be expensive. A typical solution is to represent the number in a small base, b, such that, for example, 8b is a representable machine integer. Several additions can then be performed before an overflow occurs. When the number becomes too large, we add part of it to the result, or we carry and map the remaining part back to a number that is less than b. This process is called normalization. Richard Brent used this approach in his Fortran package, MP.[2]
Lattice multiplication[]
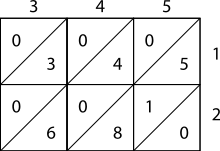

Lattice, or sieve, multiplication is algorithmically equivalent to long multiplication. It requires the preparation of a lattice (a grid drawn on paper) which guides the calculation and separates all the multiplications from the additions. It was introduced to Europe in 1202 in Fibonacci's Liber Abaci. Fibonacci described the operation as mental, using his right and left hands to carry the intermediate calculations. Matrakçı Nasuh presented 6 different variants of this method in this 16th-century book, Umdet-ul Hisab. It was widely used in Enderun schools across the Ottoman Empire.[3] Napier's bones, or Napier's rods also used this method, as published by Napier in 1617, the year of his death.
As shown in the example, the multiplicand and multiplier are written above and to the right of a lattice, or a sieve. It is found in Muhammad ibn Musa al-Khwarizmi's "Arithmetic", one of Leonardo's sources mentioned by Sigler, author of "Fibonacci's Liber Abaci", 2002.[citation needed]
- During the multiplication phase, the lattice is filled in with two-digit products of the corresponding digits labeling each row and column: the tens digit goes in the top-left corner.
- During the addition phase, the lattice is summed on the diagonals.
- Finally, if a carry phase is necessary, the answer as shown along the left and bottom sides of the lattice is converted to normal form by carrying ten's digits as in long addition or multiplication.
Example[]
The pictures on the right show how to calculate 345 × 12 using lattice multiplication. As a more complicated example, consider the picture below displaying the computation of 23,958,233 multiplied by 5,830 (multiplier); the result is 139,676,498,390. Notice 23,958,233 is along the top of the lattice and 5,830 is along the right side. The products fill the lattice and the sum of those products (on the diagonal) are along the left and bottom sides. Then those sums are totaled as shown.
2 3 9 5 8 2 3 3
+---+---+---+---+---+---+---+---+-
|1 /|1 /|4 /|2 /|4 /|1 /|1 /|1 /|
| / | / | / | / | / | / | / | / | 5
01|/ 0|/ 5|/ 5|/ 5|/ 0|/ 0|/ 5|/ 5|
+---+---+---+---+---+---+---+---+-
|1 /|2 /|7 /|4 /|6 /|1 /|2 /|2 /|
| / | / | / | / | / | / | / | / | 8
02|/ 6|/ 4|/ 2|/ 0|/ 4|/ 6|/ 4|/ 4|
+---+---+---+---+---+---+---+---+-
|0 /|0 /|2 /|1 /|2 /|0 /|0 /|0 /|
| / | / | / | / | / | / | / | / | 3
17|/ 6|/ 9|/ 7|/ 5|/ 4|/ 6|/ 9|/ 9|
+---+---+---+---+---+---+---+---+-
|0 /|0 /|0 /|0 /|0 /|0 /|0 /|0 /|
| / | / | / | / | / | / | / | / | 0
24|/ 0|/ 0|/ 0|/ 0|/ 0|/ 0|/ 0|/ 0|
+---+---+---+---+---+---+---+---+-
26 15 13 18 17 13 09 00
|
01 002 0017 00024 000026 0000015 00000013 000000018 0000000017 00000000013 000000000009 0000000000000 ————————————— 139676498390 |
= 139,676,498,390 |
Binary or Peasant multiplication[]
The binary method is also known as peasant multiplication, because it has been widely used by people who are classified as peasants and thus have not memorized the multiplication tables required for long multiplication.[4][failed verification] The algorithm was in use in ancient Egypt.[5][6] Its main advantages are that it can be taught quickly, requires no memorization, and can be performed using tokens, such as poker chips, if paper and pencil aren't available. The disadvantage is that it takes more steps than long multiplication, so it can be unwieldy for large numbers.
Description[]
On paper, write down in one column the numbers you get when you repeatedly halve the multiplier, ignoring the remainder; in a column beside it repeatedly double the multiplicand. Cross out each row in which the last digit of the first number is even, and add the remaining numbers in the second column to obtain the product.
Examples[]
This example uses peasant multiplication to multiply 11 by 3 to arrive at a result of 33.
Decimal: Binary: 11 3 1011 11 5 6 101 110 2121011001 24 1 11000 —— —————— 33 100001
Describing the steps explicitly:
- 11 and 3 are written at the top
- 11 is halved (5.5) and 3 is doubled (6). The fractional portion is discarded (5.5 becomes 5).
- 5 is halved (2.5) and 6 is doubled (12). The fractional portion is discarded (2.5 becomes 2). The figure in the left column (2) is even, so the figure in the right column (12) is discarded.
- 2 is halved (1) and 12 is doubled (24).
- All not-scratched-out values are summed: 3 + 6 + 24 = 33.
The method works because multiplication is distributive, so:

A more complicated example, using the figures from the earlier examples (23,958,233 and 5,830):
Decimal: Binary: 583023958233101101100011010110110110010010110110012915 47916466 101101100011 10110110110010010110110010 1457 95832932 10110110001 101101101100100101101100100 72819166586410110110001011011011001001011011001000364383331728101101100101101101100100101101100100001827666634561011011010110110110010010110110010000091 1533326912 1011011 1011011011001001011011001000000 45 3066653824 101101 10110110110010010110110010000000 2261333076481011010110110110010010110110010000000011 12266615296 1011 1011011011001001011011001000000000 5 24533230592 101 10110110110010010110110010000000000 249066461184101011011011001001011011001000000000001 98132922368 1 1011011011001001011011001000000000000 ———————————— 1022143253354344244353353243222210110 (before carry) 139676498390 10000010000101010111100011100111010110
Binary multiplication in computers[]
This section does not cite any sources. (January 2013) |
This is a variation of peasant multiplication.
In base 2, long multiplication reduces to a nearly trivial operation. For each '1' bit in the multiplier, shift the multiplicand by an appropriate amount, and then sum the shifted values. In some processors, it is faster to use bit shifts and additions rather than multiplication instructions, especially if the multiplier is small or always same.
Shift and add[]
Historically, computers used a "shift and add" algorithm to multiply small integers. Both base 2 long multiplication and base 2 peasant multiplication reduce to this same algorithm. In base 2, multiplying by the single digit of the multiplier reduces to a simple series of logical AND operations. Each partial product is added to a running sum as soon as each partial product is computed. Most currently available microprocessors implement this or other similar algorithms (such as Booth encoding) for various integer and floating-point sizes in hardware multipliers or in microcode.
On currently available processors, a bit-wise shift instruction is faster than a multiply instruction and can be used to multiply (shift left) and divide (shift right) by powers of two. Multiplication by a constant and division by a constant can be implemented using a sequence of shifts and adds or subtracts. For example, there are several ways to multiply by 10 using only bit-shift and addition.
((x << 2) + x) << 1 # Here 10*x is computed as (x*2^2 + x)*2 (x << 3) + (x << 1) # Here 10*x is computed as x*2^3 + x*2
In some cases such sequences of shifts and adds or subtracts will outperform hardware multipliers and especially dividers. A division by a number of the form or often can be converted to such a short sequence.


These types of sequences have to always be used for computers that do not have a "multiply" instruction,[7] and can also be used by extension to floating point numbers if one replaces the shifts with computation of 2*x as x+x, as these are logically equivalent.
Quarter square multiplication[]
Two quantities can be multiplied using quarter squares by employing the following identity involving the floor function that some sources[8][9] attribute to Babylonian mathematics (2000–1600 BC).

If one of x+y and x−y is odd, the other is odd too, thus their squares are 1 mod 4, then taking floor reduces both by a quarter; the substraction then cancels the quarters out, and discarding the remainders does not introduce any difference comparing with the same expression without the floor functions. Below is a lookup table of quarter squares with the remainder discarded for the digits 0 through 18; this allows for the multiplication of numbers up to 9×9.
| n | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| ⌊n2/4⌋ | 0 | 0 | 1 | 2 | 4 | 6 | 9 | 12 | 16 | 20 | 25 | 30 | 36 | 42 | 49 | 56 | 64 | 72 | 81 |
If, for example, you wanted to multiply 9 by 3, you observe that the sum and difference are 12 and 6 respectively. Looking both those values up on the table yields 36 and 9, the difference of which is 27, which is the product of 9 and 3.
Antoine Voisin published a table of quarter squares from 1 to 1000 in 1817 as an aid in multiplication. A larger table of quarter squares from 1 to 100000 was published by Samuel Laundy in 1856,[10] and a table from 1 to 200000 by Joseph Blater in 1888.[11]
Quarter square multipliers were used in analog computers to form an analog signal that was the product of two analog input signals. In this application, the sum and difference of two input voltages are formed using operational amplifiers. The square of each of these is approximated using piecewise linear circuits. Finally the difference of the two squares is formed and scaled by a factor of one fourth using yet another operational amplifier.
In 1980, Everett L. Johnson proposed using the quarter square method in a digital multiplier.[12] To form the product of two 8-bit integers, for example, the digital device forms the sum and difference, looks both quantities up in a table of squares, takes the difference of the results, and divides by four by shifting two bits to the right. For 8-bit integers the table of quarter squares will have 29-1=511 entries (one entry for the full range 0..510 of possible sums, the differences using only the first 256 entries in range 0..255) or 29-1=511 entries (using for negative differences the technique of 2-complements and 9-bit masking, which avoids testing the sign of differences), each entry being 16-bit wide (the entry values are from (0²/4)=0 to (510²/4)=65025).
The Quarter square multiplier technique has also benefitted 8-bit systems that do not have any support for a hardware multiplier. Charles Putney implemented this for the 6502.[13]
Fast multiplication algorithms for large inputs[]
What is the fastest algorithm for multiplication of two -digit numbers?

Complex multiplication algorithm[]
Complex multiplication normally involves four multiplications and two additions.

Or

But there is a way of reducing the number of multiplications to three.[14]
The product (a + bi) · (c + di) can be calculated in the following way.
- k1 = c · (a + b)
- k2 = a · (d − c)
- k3 = b · (c + d)
- Real part = k1 − k3
- Imaginary part = k1 + k2.
This algorithm uses only three multiplications, rather than four, and five additions or subtractions rather than two. If a multiply is more expensive than three adds or subtracts, as when calculating by hand, then there is a gain in speed. On modern computers a multiply and an add can take about the same time so there may be no speed gain. There is a trade-off in that there may be some loss of precision when using floating point.
For fast Fourier transforms (FFTs) (or any linear transformation) the complex multiplies are by constant coefficients c + di (called twiddle factors in FFTs), in which case two of the additions (d−c and c+d) can be precomputed. Hence, only three multiplies and three adds are required.[15] However, trading off a multiplication for an addition in this way may no longer be beneficial with modern floating-point units.[16]
Karatsuba multiplication[]
For systems that need to multiply numbers in the range of several thousand digits, such as computer algebra systems and bignum libraries, long multiplication is too slow. These systems may employ Karatsuba multiplication, which was discovered in 1960 (published in 1962). The heart of Karatsuba's method lies in the observation that two-digit multiplication can be done with only three rather than the four multiplications classically required. This is an example of what is now called a divide-and-conquer algorithm. Suppose we want to multiply two 2-digit base-m numbers: x1 m + x2 and y1 m + y2:
- compute x1 · y1, call the result F
- compute x2 · y2, call the result G
- compute (x1 + x2) · (y1 + y2), call the result H
- compute H − F − G, call the result K; this number is equal to x1 · y2 + x2 · y1
- compute F · m2 + K · m + G.
To compute these three products of base m numbers, we can employ the same trick again, effectively using recursion. Once the numbers are computed, we need to add them together (steps 4 and 5), which takes about n operations.
Karatsuba multiplication has a time complexity of O(nlog23) ≈ O(n1.585), making this method significantly faster than long multiplication. Because of the overhead of recursion, Karatsuba's multiplication is slower than long multiplication for small values of n; typical implementations therefore switch to long multiplication for small values of n.
Karatsuba's algorithm was the first known algorithm for multiplication that is asymptotically faster than long multiplication,[17] and can thus be viewed as the starting point for the theory of fast multiplications.
In 1963, Peter Ungar suggested setting m to i to obtain a similar reduction in the complex multiplication algorithm.[14] To multiply (a + b i) · (c + d i), follow these steps:
- compute b · d, call the result F
- compute a · c, call the result G
- compute (a + b) · (c + d), call the result H
- the imaginary part of the result is K = H − F − G = a · d + b · c
- the real part of the result is G − F = a · c − b · d
Like the algorithm in the previous section, this requires three multiplications and five additions or subtractions.
Toom–Cook[]
Another method of multiplication is called Toom–Cook or Toom-3. The Toom–Cook method splits each number to be multiplied into multiple parts. The Toom–Cook method is one of the generalizations of the Karatsuba method. A three-way Toom–Cook can do a size-3N multiplication for the cost of five size-N multiplications. This accelerates the operation by a factor of 9/5, while the Karatsuba method accelerates it by 4/3.
Although using more and more parts can reduce the time spent on recursive multiplications further, the overhead from additions and digit management also grows. For this reason, the method of Fourier transforms is typically faster for numbers with several thousand digits, and asymptotically faster for even larger numbers.
Fourier transform methods[]

The basic idea due to Strassen (1968) is to use fast polynomial multiplication to perform fast integer multiplication. The algorithm was made practical and theoretical guarantees were provided in 1971 by Schönhage and Strassen resulting in the Schönhage–Strassen algorithm.[18] The details are the following: We choose the largest integer w that will not cause overflow during the process outlined below. Then we split the two numbers into m groups of w bits as follows

We look at these numbers as polynomials in x, where x = 2w, to get,

Then we can say that,

Clearly the above setting is realized by polynomial multiplication, of two polynomials a and b. The crucial step now is to use Fast Fourier multiplication of polynomials to realize the multiplications above faster than in naive O(m2) time.
To remain in the modular setting of Fourier transforms, we look for a ring with a (2m)th root of unity. Hence we do multiplication modulo N (and thus in the Z/NZ ring). Further, N must be chosen so that there is no 'wrap around', essentially, no reductions modulo N occur. Thus, the choice of N is crucial. For example, it could be done as,

The ring Z/NZ would thus have a (2m)th root of unity, namely 8. Also, it can be checked that ck < N, and thus no wrap around will occur.
The algorithm has a time complexity of Θ(n log(n) log(log(n))) and is used in practice for numbers with more than 10,000 to 40,000 decimal digits. In 2007 this was improved by Martin Fürer (Fürer's algorithm)[19] to give a time complexity of n log(n) 2Θ(log*(n)) using Fourier transforms over complex numbers. Anindya De, Chandan Saha, Piyush Kurur and Ramprasad Saptharishi[20] gave a similar algorithm using modular arithmetic in 2008 achieving the same running time. In context of the above material, what these latter authors have achieved is to find N much less than 23k + 1, so that Z/NZ has a (2m)th root of unity. This speeds up computation and reduces the time complexity. However, these latter algorithms are only faster than Schönhage–Strassen for impractically large inputs.
In March 2019, and Joris van der Hoeven released a paper describing an O(n log n) multiplication algorithm.[21][22][23][24]
Using number-theoretic transforms instead of discrete Fourier transforms avoids rounding error problems by using modular arithmetic instead of floating-point arithmetic. In order to apply the factoring which enables the FFT to work, the length of the transform must be factorable to small primes and must be a factor of N − 1, where N is the field size. In particular, calculation using a Galois field GF(k2), where k is a Mersenne prime, allows the use of a transform sized to a power of 2; e.g. k = 231 − 1 supports transform sizes up to 232.
Lower bounds[]
There is a trivial lower bound of Ω(n) for multiplying two n-bit numbers on a single processor; no matching algorithm (on conventional machines, that is on Turing equivalent machines) nor any sharper lower bound is known. Multiplication lies outside of AC0[p] for any prime p, meaning there is no family of constant-depth, polynomial (or even subexponential) size circuits using AND, OR, NOT, and MODp gates that can compute a product. This follows from a constant-depth reduction of MODq to multiplication.[25] Lower bounds for multiplication are also known for some classes of branching programs.[26]
Polynomial multiplication[]
All the above multiplication algorithms can also be expanded to multiply polynomials. For instance the Strassen algorithm may be used for polynomial multiplication[27] Alternatively the Kronecker substitution technique may be used to convert the problem of multiplying polynomials into a single binary multiplication.[28]
Long multiplication methods can be generalised to allow the multiplication of algebraic formulae:
14ac - 3ab + 2 multiplied by ac - ab + 1
14ac -3ab 2
ac -ab 1
————————————————————
14a2c2 -3a2bc 2ac
-14a2bc 3 a2b2 -2ab
14ac -3ab 2
———————————————————————————————————————
14a2c2 -17a2bc 16ac 3a2b2 -5ab +2
=======================================[29]
As a further example of column based multiplication, consider multiplying 23 long tons (t), 12 hundredweight (cwt) and 2 quarters (qtr) by 47. This example uses avoirdupois measures: 1 t = 20 cwt, 1 cwt = 4 qtr.
t cwt qtr
23 12 2
47 x
————————————————
141 94 94
940 470
29 23
————————————————
1110 587 94
————————————————
1110 7 2
================= Answer: 1110 ton 7 cwt 2 qtr
First multiply the quarters by 47, the result 94 is written into the first workspace. Next, multiply cwt 12*47 = (2 + 10)*47 but don't add up the partial results (94, 470) yet. Likewise multiply 23 by 47 yielding (141, 940). The quarters column is totaled and the result placed in the second workspace (a trivial move in this case). 94 quarters is 23 cwt and 2 qtr, so place the 2 in the answer and put the 23 in the next column left. Now add up the three entries in the cwt column giving 587. This is 29 t 7 cwt, so write the 7 into the answer and the 29 in the column to the left. Now add up the tons column. There is no adjustment to make, so the result is just copied down.
The same layout and methods can be used for any traditional measurements and non-decimal currencies such as the old British £sd system.
See also[]
- Binary multiplier
- Division algorithm
- Logarithm
- Mental calculation
- Prosthaphaeresis
- Slide rule
- Trachtenberg system
- Horner scheme for evaluating of a polynomial
- Residue number system § Multiplication for another fast multiplication algorithm, specially efficient when many operations are done in sequence, such as in linear algebra
- Dadda multiplier
- Wallace tree
References[]
- ^ Gary Eason, Back to school for parents, BBC News, 13 February 2000
Rob Eastaway, Why parents can't do maths today, BBC News, 10 September 2010 - ^ Brent, Richard P (March 1978). "A Fortran Multiple-Precision Arithmetic Package". ACM Transactions on Mathematical Software. 4: 57–70. CiteSeerX 10.1.1.117.8425. doi:10.1145/355769.355775. S2CID 8875817.
- ^ Corlu, M. S., Burlbaw, L. M., Capraro, R. M., Corlu, M. A.,& Han, S. (2010). The Ottoman Palace School Enderun and The Man with Multiple Talents, Matrakçı Nasuh. Journal of the Korea Society of Mathematical Education Series D: Research in Mathematical Education. 14(1), pp. 19–31.
- ^ Bogomolny, Alexander. "Peasant Multiplication". www.cut-the-knot.org. Retrieved 2017-11-04.
- ^ D. Wells (1987). The Penguin Dictionary of Curious and Interesting Numbers. Penguin Books. p. 44.
- ^ Cool Multiplication Math Trick, retrieved 2020-03-14
- ^ "Novel Methods of Integer Multiplication and Division" by G. Reichborn-Kjennerud
- ^ McFarland, David (2007), Quarter Tables Revisited: Earlier Tables, Division of Labor in Table Construction, and Later Implementations in Analog Computers, p. 1
- ^ Robson, Eleanor (2008). Mathematics in Ancient Iraq: A Social History. p. 227. ISBN 978-0691091822.
- ^ "Reviews", The Civil Engineer and Architect's Journal: 54–55, 1857.
- ^ Holmes, Neville (2003), "Multiplying with quarter squares", The Mathematical Gazette, 87 (509): 296–299, doi:10.1017/S0025557200172778, JSTOR 3621048.
- ^ Everett L., Johnson (March 1980), "A Digital Quarter Square Multiplier", IEEE Transactions on Computers, Washington, DC, USA: IEEE Computer Society, C-29 (3), pp. 258–261, doi:10.1109/TC.1980.1675558, ISSN 0018-9340, S2CID 24813486
- ^ Putney, Charles (Mar 1986), "Fastest 6502 Multiplication Yet", Apple Assembly Line, 6 (6)
- ^ Jump up to: a b Knuth, Donald E. (1988), The Art of Computer Programming volume 2: Seminumerical algorithms, Addison-Wesley, pp. 519, 706
- ^ P. Duhamel and M. Vetterli, Fast Fourier transforms: A tutorial review and a state of the art" Archived 2014-05-29 at the Wayback Machine, Signal Processing vol. 19, pp. 259–299 (1990), section 4.1.
- ^ S. G. Johnson and M. Frigo, "A modified split-radix FFT with fewer arithmetic operations," IEEE Trans. Signal Process. vol. 55, pp. 111–119 (2007), section IV.
- ^ D. Knuth, The Art of Computer Programming, vol. 2, sec. 4.3.3 (1998)
- ^ A. Schönhage and V. Strassen, "Schnelle Multiplikation großer Zahlen", Computing 7 (1971), pp. 281–292.
- ^ Fürer, M. (2007). "Faster Integer Multiplication" in Proceedings of the thirty-ninth annual ACM symposium on Theory of computing, June 11–13, 2007, San Diego, California, USA
- ^ Anindya De, Piyush P Kurur, Chandan Saha, Ramprasad Saptharishi. Fast Integer Multiplication Using Modular Arithmetic. Symposium on Theory of Computation (STOC) 2008.
- ^ David Harvey; Joris Van Der Hoeven (2019). Integer multiplication in time O(n log n) (Report). HAL.
- ^ KWRegan (2019-03-29). "Integer Multiplication in NlogN Time". Gödel's Lost Letter and P=NP. Retrieved 2019-05-03.
- ^ Hartnett, Kevin. "Mathematicians Discover the Perfect Way to Multiply". Quanta Magazine. Retrieved 2019-05-03.
- ^ Harvey, David. "Integer multiplication in time O(n log n)".
- ^ Sanjeev Arora and Boaz Barak, Computational Complexity: A Modern Approach, Cambridge University Press, 2009.
- ^ Farid Ablayev and Marek Karpinski, A lower bound for integer multiplication on randomized ordered read-once branching programs, Information and Computation 186 (2003), 78–89.
- ^ "Strassen algorithm for polynomial multiplication". Everything2.
- ^ von zur Gathen, Joachim; Gerhard, Jürgen (1999), Modern Computer Algebra, Cambridge University Press, pp. 243–244, ISBN 978-0-521-64176-0.
- ^ Castle, Frank (1900). Workshop Mathematics. London: MacMillan and Co. p. 74.
Further reading[]
- Warren Jr., Henry S. (2013). Hacker's Delight (2 ed.). Addison Wesley - Pearson Education, Inc. ISBN 978-0-321-84268-8.
- Savard, John J. G. (2018) [2006]. "Advanced Arithmetic Techniques". quadibloc. Archived from the original on 2018-07-03. Retrieved 2018-07-16.
- Johansson, Kenny. Low Power and Low Complexity Shift-and-Add Based Computations (PDF) (Dissertation thesis). Linköping Studies in Science and Technology (1 ed.). Linköping, Sweden: Department of Electrical Engineering, Linköping University. ISBN 978-91-7393-836-5. ISSN 0345-7524. No. 1201. Archived (PDF) from the original on 2017-08-13. Retrieved 2021-08-23. (x+268 pages)
External links[]
Basic arithmetic[]
- The Many Ways of Arithmetic in UCSMP Everyday Mathematics
- A Powerpoint presentation about ancient mathematics
- Lattice Multiplication Flash Video
Advanced algorithms[]
- Computer arithmetic algorithms
- Multiplication