Probability distribution
| Part of a series on statistics |
| Probability theory |
|---|
 |
|
|
|
|
In probability theory and statistics, a probability distribution is the mathematical function that gives the probabilities of occurrence of different possible outcomes for an experiment.[1][2] It is a mathematical description of a random phenomenon in terms of its sample space and the probabilities of events (subsets of the sample space).[3]
For instance, if X is used to denote the outcome of a coin toss ("the experiment"), then the probability distribution of X would take the value 0.5 (1 in 2 or 1/2) for X = heads, and 0.5 for X = tails (assuming that the coin is fair). Examples of random phenomena include the weather condition in a future date, the height of a randomly selected person, the fraction of male students in a school, the results of a survey to be conducted, etc.[4]
Introduction[]

A probability distribution is a mathematical description of the probabilities of events, subsets of the sample space. The sample space, often denoted by ,[5] is the set of all possible outcomes of a random phenomenon being observed; it may be any set: a set of real numbers, a set of vectors, a set of arbitrary non-numerical values, etc. For example, the sample space of a coin flip would be Ω = {heads, tails}.

To define probability distributions for the specific case of random variables (so the sample space can be seen as a numeric set), it is common to distinguish between discrete and continuous random variables. In the discrete case, it is sufficient to specify a probability mass function assigning a probability to each possible outcome: for example, when throwing a fair die, each of the six values 1 to 6 has the probability 1/6. The probability of an event is then defined to be the sum of the probabilities of the outcomes that satisfy the event; for example, the probability of the event "the die rolls an even value" is


In contrast, when a random variable takes values from a continuum then typically, any individual outcome has probability zero and only events that include infinitely many outcomes, such as intervals, can have positive probability. For example, consider measuring the weight of a piece of ham in the supermarket, and assume the scale has many digits of precision. The probability that it weighs exactly 500 g is zero, as it will most likely have some non-zero decimal digits. Nevertheless, one might demand, in quality control, that a package of "500 g" of ham must weigh between 490 g and 510 g with at least 98% probability, and this demand is less sensitive to the accuracy of measurement instruments.
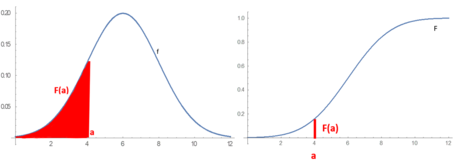
Continuous probability distributions can be described in several ways. The probability density function describes the infinitesimal probability of any given value, and the probability that the outcome lies in a given interval can be computed by integrating the probability density function over that interval.[6] An alternative description of the distribution is by means of the cumulative distribution function, which describes the probability that the random variable is no larger than a given value (i.e., P(X < x) for some x). The cumulative distribution function is the area under the probability density function from to x, as described by the picture to the right.[7]

General definition[]
A probability distribution can be described in various forms, such as by a probability mass function or a cumulative distribution function. One of the most general descriptions, which applies for continuous and discrete variables, is by means of a probability function whose input space is related to the sample space, and gives a probability as its output.[8]


The probability function P can take as argument subsets of the sample space itself, as in the coin toss example, where the function P was defined so that P(heads) = 0.5 and P(tails) = 0.5. However, because of the widespread use of random variables, which transform the sample space into a set of numbers (e.g., , ), it is more common to study probability distributions whose argument are subsets of these particular kinds of sets (number sets),[9] and all probability distributions discussed in this article are of this type. It is common to denote as P(X E) the probability that a certain variable X belongs to a certain event E.[4][10]



The above probability function only characterizes a probability distribution if it satisfies all the Kolmogorov axioms, that is:
- , so the probability is non-negative
- , so no probability exceeds
- for any disjoint family of sets





The concept of probability function is made more rigorous by defining it as the element of a probability space , where is the set of possible outcomes, is the set of all subsets whose probability can be measured, and is the probability function, or probability measure, that assigns a probability to each of these measurable subsets .[11]





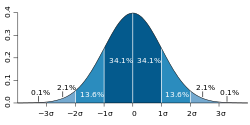
Probability distributions are generally divided into two classes. A discrete probability distribution is applicable to the scenarios where the set of possible outcomes is discrete (e.g. a coin toss, a roll of a die) and the probabilities are encoded by a discrete list of the probabilities of the outcomes; in this case the discrete probability distribution is known as probability mass function. On the other hand, continuous probability distributions are applicable to scenarios where the set of possible outcomes can take on values in a continuous range (e.g. real numbers), such as the temperature on a given day. In the case of real numbers, the continuous probability distribution is the cumulative distribution function. In general, in the continuous case, probabilities are described by a probability density function, and the probability distribution is by definition the integral of the probability density function.[4][6][10] The normal distribution is a commonly encountered continuous probability distribution. More complex experiments, such as those involving stochastic processes defined in continuous time, may demand the use of more general probability measures.
A probability distribution whose sample space is one-dimensional (for example real numbers, list of labels, ordered labels or binary) is called univariate, while a distribution whose sample space is a vector space of dimension 2 or more is called multivariate. A univariate distribution gives the probabilities of a single random variable taking on various different values; a multivariate distribution (a joint probability distribution) gives the probabilities of a random vector – a list of two or more random variables – taking on various combinations of values. Important and commonly encountered univariate probability distributions include the binomial distribution, the hypergeometric distribution, and the normal distribution. A commonly encountered multivariate distribution is the multivariate normal distribution.
Besides the probability function, the cumulative distribution function, the probability mass function and the probability density function, the moment generating function and the characteristic function also serve to identify a probability distribution, as they uniquely determine an underlying cumulative distribution function.[12]
Terminology[]
Some key concepts and terms, widely used in the literature on the topic of probability distributions, are listed below.[1]
Functions for discrete variables[]
- Probability function: describes the probability that the event from the sample space occurs.[8]
- Probability mass function (pmf): function that gives the probability that a discrete random variable is equal to some value.
- Frequency distribution: a table that displays the frequency of various outcomes in a sample.
- Relative frequency distribution: a frequency distribution where each value has been divided (normalized) by a number of outcomes in a sample (i.e. sample size).
- Discrete probability distribution function: general term to indicate the way the total probability of 1 is distributed over all various possible outcomes (i.e. over entire population) for discrete random variable.
- Cumulative distribution function: function evaluating the probability that will take a value less than or equal to for a discrete random variable.
- Categorical distribution: for discrete random variables with a finite set of values.



Functions for continuous variables[]
- Probability density function (pdf): function whose value at any given sample (or point) in the sample space (the set of possible values taken by the random variable) can be interpreted as providing a relative likelihood that the value of the random variable would equal that sample.
- Continuous probability distribution function: most often reserved for continuous random variables.
- Cumulative distribution function: function evaluating the probability that will take a value less than or equal to for a continuous variable.
- Quantile function: the inverse of the cumulative distribution function. Gives such that, with probability , will not exceed .

Basic terms[]
- Mode: for a discrete random variable, the value with highest probability; for a continuous random variable, a location at which the probability density function has a local peak.
- Support: set of values that can be assumed with non-zero probability by the random variable. For a random variable , it is sometimes denoted as .[5]
- Tail:[13] the regions close to the bounds of the random variable, if the pmf or pdf are relatively low therein. Usually has the form , or a union thereof.
- Head:[13] the region where the pmf or pdf is relatively high. Usually has the form .
- Expected value or mean: the weighted average of the possible values, using their probabilities as their weights; or the continuous analog thereof.
- Median: the value such that the set of values less than the median, and the set greater than the median, each have probabilities no greater than one-half.
- Variance: the second moment of the pmf or pdf about the mean; an important measure of the dispersion of the distribution.
- Standard deviation: the square root of the variance, and hence another measure of dispersion.
- Quantile: the q-quantile is the value such that .
- Symmetry: a property of some distributions in which the portion of the distribution to the left of a specific value (usually the median) is a mirror image of the portion to its right.
- Skewness: a measure of the extent to which a pmf or pdf "leans" to one side of its mean. The third standardized moment of the distribution.
- Kurtosis: a measure of the "fatness" of the tails of a pmf or pdf. The fourth standardized moment of the distribution.





Discrete probability distribution[]

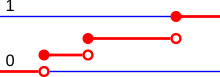
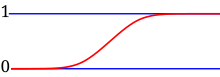
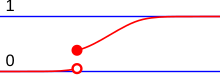
A discrete probability distribution is the probability distribution of a random variable that can take on only a countable number of values.[14] In the case where the range of values is countably infinite, these values have to decline to zero fast enough for the probabilities to add up to 1. For example, if for n = 1, 2, ..., the sum of probabilities would be 1/2 + 1/4 + 1/8 + ... = 1.

Well-known discrete probability distributions used in statistical modeling include the Poisson distribution, the Bernoulli distribution, the binomial distribution, the geometric distribution, and the negative binomial distribution.[3] Additionally, the discrete uniform distribution is commonly used in computer programs that make equal-probability random selections between a number of choices.
When a sample (a set of observations) is drawn from a larger population, the sample points have an empirical distribution that is discrete, and which provides information about the population distribution.
Cumulative distribution function[]
Equivalently to the above, a discrete random variable can be defined as a random variable whose cumulative distribution function (cdf) increases only by jump discontinuities—that is, its cdf increases only where it "jumps" to a higher value, and is constant between those jumps. Note however that the points where the cdf jumps may form a dense set of the real numbers. The points where jumps occur are precisely the values which the random variable may take.
Delta-function representation[]
Consequently, a discrete probability distribution is often represented as a generalized probability density function involving Dirac delta functions, which substantially unifies the treatment of continuous and discrete distributions. This is especially useful when dealing with probability distributions involving both a continuous and a discrete part.[15]
Indicator-function representation[]
For a discrete random variable X, let u0, u1, ... be the values it can take with non-zero probability. Denote

These are disjoint sets, and for such sets

It follows that the probability that X takes any value except for u0, u1, ... is zero, and thus one can write X as

except on a set of probability zero, where is the indicator function of A. This may serve as an alternative definition of discrete random variables.

One-point distribution[]
A special case is the discrete distribution of a random variable that can take on only one fixed value; in other words, it is a deterministic distribution. Expressed formally, the random variable has a one-point distribution if it has a possible outcome such that [16] All other possible outcomes then have probability 0. Its cumulative distribution function jumps immediately from 0 to 1.

Continuous probability distribution[]
A continuous probability distribution is a probability distribution whose support is an uncountable set, such as an interval in the real line.[17] They are uniquely characterized by a cumulative distribution function that can be used to calculate the probability for each subset of the support. There are many examples of continuous probability distributions: normal, uniform, chi-squared, and others.
A random variable has a continuous probability distribution if there is a function such that for each interval the probability of belonging to is given by the integral of over .[18] For example, if , then we would have:[19]
![{\displaystyle f:\mathbb {R} \rightarrow [0,\infty ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b3b6e6b04c174d818387506a1ac184a0fd4ff8b4)



![{\displaystyle I=[a,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6d6214bb3ce7f00e496c0706edd1464ac60b73b5)
![{\displaystyle \operatorname {P} \left[a\leq X\leq b\right]=\int _{a}^{b}f(x)\,dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/24100c8d991e874ff860e5e1e5ba9564637b6491)
In particular, the probability for to take any single value (that is, ) is zero, because an integral with coinciding upper and lower limits is always equal to zero. A variable that satisfies the above is called continuous random variable. Its cumulative density function is defined as


![{\displaystyle F(x)=\operatorname {P} \left[-\infty <X\leq x\right]=\int _{-\infty }^{x}f(x)\,dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/39c8cbe734b9ee1002f72a07d19054cbe55ae650)
which, by this definition, has the properties:
- is non-decreasing;
- ;
- and ;
- ; and
- is continuous due to the Riemann integral properties.[20]





It is also possible to think in the opposite direction, which allows more flexibility: if is a function that satisfies all but the last of the properties above, then represents the cumulative density function for some random variable: a discrete random variable if is a step function, and a continuous random variable otherwise.[21] This allows for continuous distributions that have a cumulative density function, but not a probability density function, such as the Cantor distribution.

It is often necessary to generalize the above definition for more arbitrary subsets of the real line. In these contexts, a continuous probability distribution is defined as a probability distribution with a cumulative distribution function that is absolutely continuous. Equivalently, it is a probability distribution on the real numbers that is absolutely continuous with respect to the Lebesgue measure. Such distributions can be represented by their probability density functions. If is such an absolutely continuous random variable, then it has a probability density function , and its probability of falling into a Lebesgue-measurable set is:


![{\displaystyle \operatorname {P} \left[X\in A\right]=\int _{A}f(x)\,d\mu }](https://wikimedia.org/api/rest_v1/media/math/render/svg/cbe029d0506f32f586431aec415198c06cac7ea2)
where is the Lebesgue measure.

Note on terminology: some authors use the term "continuous distribution" to denote distributions whose cumulative distribution functions are continuous, rather than absolutely continuous. These distributions are the ones such that for all . This definition includes the (absolutely) continuous distributions defined above, but it also includes singular distributions, which are neither absolutely continuous nor discrete nor a mixture of those, and do not have a density. An example is given by the Cantor distribution.


Kolmogorov definition[]
In the measure-theoretic formalization of probability theory, a random variable is defined as a measurable function from a probability space to a measurable space . Given that probabilities of events of the form satisfy Kolmogorov's probability axioms, the probability distribution of X is the pushforward measure of , which is a probability measure on satisfying .[22][23][24]





Other kinds of distributions[]
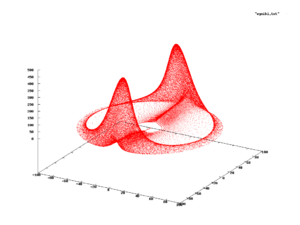
Continuous and discrete distributions with support on or are extremely useful to model a myriad of phenomena,[4][7] since most practical distributions are supported on relatively simple subsets, such as hypercubes or balls. However, this is not always the case, and there exist phenomena with supports that are actually complicated curves within some space or similar. In these cases, the probability distribution is supported on the image of such curve, and is likely to be determined empirically, rather than finding a closed formula for it.[25]


![{\displaystyle \gamma :[a,b]\rightarrow \mathbb {R} ^{n}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/58e103c376cd9ea50b5c12c8f5398ded4d2a3577)

One example is shown in the figure to the right, which displays the evolution of a system of differential equations (commonly known as the Rabinovich–Fabrikant equations) that can be used to model the behaviour of Langmuir waves in plasma.[26] When this phenomenon is studied, the observed states from the subset are as indicated in red. So one could ask what is the probability of observing a state in a certain position of the red subset; if such a probability exists, it is called the probability measure of the system.[27][25]
This kind of complicated support appears quite frequently in dynamical systems. It is not simple to establish that the system has a probability measure, and the main problem is the following. Let be instants in time and a subset of the support; if the probability measure exists for the system, one would expect the frequency of observing states inside set would be equal in interval and , which might not happen; for example, it could oscillate similar to a sine, , whose limit when does not converge. Formally, the measure exists only if the limit of the relative frequency converges when the system is observed into the infinite future.[28] The branch of dynamical systems that studies the existence of a probability measure is ergodic theory.


![{\displaystyle [t_{1},t_{2}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6e35e13fa8221f864808f15cafa3d1467b5d78ce)
![{\displaystyle [t_{2},t_{3}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/82eae695d40fda9d1b713787d35efa48d9a95478)


Note that even in these cases, the probability distribution, if it exists, might still be termed "continuous" or "discrete" depending on whether the support is uncountable or countable, respectively.
Random number generation[]
Most algorithms are based on a pseudorandom number generator that produces numbers X that are uniformly distributed in the half-open interval [0,1). These random variates X are then transformed via some algorithm to create a new random variate having the required probability distribution. With this source of uniform pseudo-randomness, realizations of any random variable can be generated.[29]
For example, suppose has a uniform distribution between 0 and 1. To construct a random Bernoulli variable for some , we define



so that

This random variable X has a Bernoulli distribution with parameter .[29] Note that this is a transformation of discrete random variable.
For a distribution function of a continuous random variable, a continuous random variable must be constructed. , an inverse function of , relates to the uniform variable :


For example, suppose a random variable that has an exponential distribution must be constructed.


so and if has a distribution, then the random variable is defined by . This has an exponential distribution of .[29]




A frequent problem in statistical simulations (the Monte Carlo method) is the generation of pseudo-random numbers that are distributed in a given way.
Common probability distributions and their applications[]
The concept of the probability distribution and the random variables which they describe underlies the mathematical discipline of probability theory, and the science of statistics. There is spread or variability in almost any value that can be measured in a population (e.g. height of people, durability of a metal, sales growth, traffic flow, etc.); almost all measurements are made with some intrinsic error; in physics, many processes are described probabilistically, from the kinetic properties of gases to the quantum mechanical description of fundamental particles. For these and many other reasons, simple numbers are often inadequate for describing a quantity, while probability distributions are often more appropriate.
The following is a list of some of the most common probability distributions, grouped by the type of process that they are related to. For a more complete list, see list of probability distributions, which groups by the nature of the outcome being considered (discrete, continuous, multivariate, etc.)
All of the univariate distributions below are singly peaked; that is, it is assumed that the values cluster around a single point. In practice, actually observed quantities may cluster around multiple values. Such quantities can be modeled using a mixture distribution.
Linear growth (e.g. errors, offsets)[]
- Normal distribution (Gaussian distribution), for a single such quantity; the most commonly used continuous distribution
Exponential growth (e.g. prices, incomes, populations)[]
- Log-normal distribution, for a single such quantity whose log is normally distributed
- Pareto distribution, for a single such quantity whose log is exponentially distributed; the prototypical power law distribution
Uniformly distributed quantities[]
- Discrete uniform distribution, for a finite set of values (e.g. the outcome of a fair die)
- Continuous uniform distribution, for continuously distributed values
Bernoulli trials (yes/no events, with a given probability)[]
- Basic distributions:
- Bernoulli distribution, for the outcome of a single Bernoulli trial (e.g. success/failure, yes/no)
- Binomial distribution, for the number of "positive occurrences" (e.g. successes, yes votes, etc.) given a fixed total number of independent occurrences
- Negative binomial distribution, for binomial-type observations but where the quantity of interest is the number of failures before a given number of successes occurs
- Geometric distribution, for binomial-type observations but where the quantity of interest is the number of failures before the first success; a special case of the negative binomial distribution
- Related to sampling schemes over a finite population:
- Hypergeometric distribution, for the number of "positive occurrences" (e.g. successes, yes votes, etc.) given a fixed number of total occurrences, using sampling without replacement
- Beta-binomial distribution, for the number of "positive occurrences" (e.g. successes, yes votes, etc.) given a fixed number of total occurrences, sampling using a Pólya urn model (in some sense, the "opposite" of sampling without replacement)
Categorical outcomes (events with K possible outcomes)[]
- Categorical distribution, for a single categorical outcome (e.g. yes/no/maybe in a survey); a generalization of the Bernoulli distribution
- Multinomial distribution, for the number of each type of categorical outcome, given a fixed number of total outcomes; a generalization of the binomial distribution
- Multivariate hypergeometric distribution, similar to the multinomial distribution, but using sampling without replacement; a generalization of the hypergeometric distribution
Poisson process (events that occur independently with a given rate)[]
- Poisson distribution, for the number of occurrences of a Poisson-type event in a given period of time
- Exponential distribution, for the time before the next Poisson-type event occurs
- Gamma distribution, for the time before the next k Poisson-type events occur
Absolute values of vectors with normally distributed components[]
- Rayleigh distribution, for the distribution of vector magnitudes with Gaussian distributed orthogonal components. Rayleigh distributions are found in RF signals with Gaussian real and imaginary components.
- Rice distribution, a generalization of the Rayleigh distributions for where there is a stationary background signal component. Found in Rician fading of radio signals due to multipath propagation and in MR images with noise corruption on non-zero NMR signals.
Normally distributed quantities operated with sum of squares[]
- Chi-squared distribution, the distribution of a sum of squared standard normal variables; useful e.g. for inference regarding the sample variance of normally distributed samples (see chi-squared test)
- Student's t distribution, the distribution of the ratio of a standard normal variable and the square root of a scaled chi squared variable; useful for inference regarding the mean of normally distributed samples with unknown variance (see Student's t-test)
- F-distribution, the distribution of the ratio of two scaled chi squared variables; useful e.g. for inferences that involve comparing variances or involving R-squared (the squared correlation coefficient)
As conjugate prior distributions in Bayesian inference[]
- Beta distribution, for a single probability (real number between 0 and 1); conjugate to the Bernoulli distribution and binomial distribution
- Gamma distribution, for a non-negative scaling parameter; conjugate to the rate parameter of a Poisson distribution or exponential distribution, the precision (inverse variance) of a normal distribution, etc.
- Dirichlet distribution, for a vector of probabilities that must sum to 1; conjugate to the categorical distribution and multinomial distribution; generalization of the beta distribution
- Wishart distribution, for a symmetric non-negative definite matrix; conjugate to the inverse of the covariance matrix of a multivariate normal distribution; generalization of the gamma distribution[30]
Some specialized applications of probability distributions[]
- The cache language models and other statistical language models used in natural language processing to assign probabilities to the occurrence of particular words and word sequences do so by means of probability distributions.
- In quantum mechanics, the probability density of finding the particle at a given point is proportional to the square of the magnitude of the particle's wavefunction at that point (see Born rule). Therefore, the probability distribution function of the position of a particle is described by , probability that the particle's position x will be in the interval a ≤ x ≤ b in dimension one, and a similar triple integral in dimension three. This is a key principle of quantum mechanics.[31]
- Probabilistic load flow in power-flow study explains the uncertainties of input variables as probability distribution and provides the power flow calculation also in term of probability distribution.[32]
- Prediction of natural phenomena occurrences based on previous frequency distributions such as tropical cyclones, hail, time in between events, etc.[33]

See also[]
- Conditional probability distribution
- Joint probability distribution
- Quasiprobability distribution
- Empirical probability distribution
- Histogram
- Riemann–Stieltjes integral application to probability theory
Lists[]
- List of probability distributions
- List of statistical topics
References[]
Citations[]
- ^ Jump up to: a b Everitt, Brian. (2006). The Cambridge dictionary of statistics (3rd ed.). Cambridge, UK: Cambridge University Press. ISBN 978-0-511-24688-3. OCLC 161828328.
- ^ Ash, Robert B. (2008). Basic probability theory (Dover ed.). Mineola, N.Y.: Dover Publications. pp. 66–69. ISBN 978-0-486-46628-6. OCLC 190785258.
- ^ Jump up to: a b Evans, Michael; Rosenthal, Jeffrey S. (2010). Probability and statistics: the science of uncertainty (2nd ed.). New York: W.H. Freeman and Co. p. 38. ISBN 978-1-4292-2462-8. OCLC 473463742.
- ^ Jump up to: a b c d Ross, Sheldon M. (2010). A first course in probability. Pearson.
- ^ Jump up to: a b "List of Probability and Statistics Symbols". Math Vault. 2020-04-26. Retrieved 2020-09-10.
- ^ Jump up to: a b "1.3.6.1. What is a Probability Distribution". www.itl.nist.gov. Retrieved 2020-09-10.
- ^ Jump up to: a b A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.CS1 maint: others (link)
- ^ Jump up to: a b Chapters 1 and 2 of Vapnik (1998)
- ^ Walpole, R.E.; Myers, R.H.; Myers, S.L.; Ye, K. (1999). Probability and statistics for engineers. Prentice Hall.
- ^ Jump up to: a b DeGroot, Morris H.; Schervish, Mark J. (2002). Probability and Statistics. Addison-Wesley.
- ^ Billingsley, P. (1986). Probability and measure. Wiley. ISBN 9780471804789.
- ^ Shephard, N.G. (1991). "From characteristic function to distribution function: a simple framework for the theory". Econometric Theory. 7 (4): 519–529. doi:10.1017/S0266466600004746.
- ^ Jump up to: a b More information and examples can be found in the articles Heavy-tailed distribution, Long-tailed distribution, fat-tailed distribution
- ^ Erhan, Çınlar (2011). Probability and stochastics. New York: Springer. p. 51. ISBN 9780387878591. OCLC 710149819.
- ^ Khuri, André I. (March 2004). "Applications of Dirac's delta function in statistics". International Journal of Mathematical Education in Science and Technology. 35 (2): 185–195. doi:10.1080/00207390310001638313. ISSN 0020-739X. S2CID 122501973.
- ^ Fisz, Marek (1963). Probability Theory and Mathematical Statistics (3rd ed.). John Wiley & Sons. p. 104. ISBN 0-471-26250-1.
- ^ Sheldon M. Ross (2010). Introduction to probability models. Elsevier.
- ^ Chapter 3.2 of DeGroot & Schervish (2002)
- ^ Bourne, Murray. "11. Probability Distributions - Concepts". www.intmath.com. Retrieved 2020-09-10.
- ^ Chapter 7 of Burkill, J.C. (1978). A first course in mathematical analysis. Cambridge University Press.
- ^ See Theorem 2.1 of Vapnik (1998), or Lebesgue's decomposition theorem. The section #Delta-function_representation may also be of interest.
- ^ W., Stroock, Daniel (1999). Probability theory : an analytic view (Rev. ed.). Cambridge [England]: Cambridge University Press. p. 11. ISBN 978-0521663496. OCLC 43953136.
- ^ Kolmogorov, Andrey (1950) [1933]. Foundations of the theory of probability. New York, USA: Chelsea Publishing Company. pp. 21–24.
- ^ Joyce, David (2014). "Axioms of Probability" (PDF). Clark University. Retrieved December 5, 2019.
- ^ Jump up to: a b Alligood, K.T.; Sauer, T.D.; Yorke, J.A. (1996). Chaos: an introduction to dynamical systems. Springer.
- ^ Rabinovich, M.I.; Fabrikant, A.L. (1979). "Stochastic self-modulation of waves in nonequilibrium media". J. Exp. Theor. Phys. 77: 617–629. Bibcode:1979JETP...50..311R.
- ^ Section 1.9 of Ross, S.M.; Peköz, E.A. (2007). A second course in probability (PDF).
- ^ Walters, Peter (2000). An Introduction to Ergodic Theory. Springer.
- ^ Jump up to: a b c Dekking, Frederik Michel; Kraaikamp, Cornelis; Lopuhaä, Hendrik Paul; Meester, Ludolf Erwin (2005), "Why probability and statistics?", A Modern Introduction to Probability and Statistics, Springer London, pp. 1–11, doi:10.1007/1-84628-168-7_1, ISBN 978-1-85233-896-1
- ^ Bishop, Christopher M. (2006). Pattern recognition and machine learning. New York: Springer. ISBN 0-387-31073-8. OCLC 71008143.
- ^ Chang, Raymond. Physical chemistry for the chemical sciences. Thoman, John W., Jr., 1960-. [Mill Valley, California]. pp. 403–406. ISBN 978-1-68015-835-9. OCLC 927509011.
- ^ Chen, P.; Chen, Z.; Bak-Jensen, B. (April 2008). "Probabilistic load flow: A review". 2008 Third International Conference on Electric Utility Deregulation and Restructuring and Power Technologies. pp. 1586–1591. doi:10.1109/drpt.2008.4523658. ISBN 978-7-900714-13-8. S2CID 18669309.
- ^ Maity, Rajib (2018-04-30). Statistical methods in hydrology and hydroclimatology. Singapore. ISBN 978-981-10-8779-0. OCLC 1038418263.
Sources[]
- den Dekker, A. J.; Sijbers, J. (2014). "Data distributions in magnetic resonance images: A review". . 30 (7): 725–741. doi:10.1016/j.ejmp.2014.05.002. PMID 25059432.
- Vapnik, Vladimir Naumovich (1998). Statistical Learning Theory. John Wiley and Sons.
External links[]
| Wikimedia Commons has media related to Probability distribution. |
- "Probability distribution", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Field Guide to Continuous Probability Distributions, Gavin E. Crooks.
| hide Theory of probability distributions | ||
|---|---|---|
|  | |
| ||
| ||
| hide Statistics | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||
| |||||||||||||||||||||
| |||||||||||||||||||||
| |||||||||||||||||||||
| |||||||||||||||||||||
| |||||||||||||||||||||
| |||||||||||||||||||||
| |||||||||||||||||||||
| show Authority control |
|---|
- Probability distributions
- Mathematical and quantitative methods (economics)