Family of probability distributions often used to model tails or extreme values
This article is about a particular family of continuous distributions referred to as the generalized Pareto distribution. For the hierarchy of generalized Pareto distributions, see Pareto distribution.
This article needs additional citations for verification. Please help by adding citations to reliable sources. Unsourced material may be challenged and removed. Find sources: – ···scholar·JSTOR(March 2012) (Learn how and when to remove this template message)
Generalized Pareto distribution
Probability density function
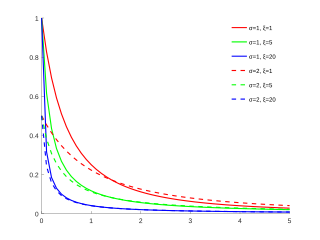
GPD distribution functions for and different values of and
In statistics, the generalized Pareto distribution (GPD) is a family of continuous probability distributions. It is often used to model the tails of another distribution. It is specified by three parameters: location , scale , and shape .[1][2] Sometimes it is specified by only scale and shape[3] and sometimes only by its shape parameter. Some references give the shape parameter as .[4]
With shape and location , the GPD is equivalent to the Pareto distribution with scale and shape .
If , , , then [1]. (exGPD stands for the exponentiated generalized Pareto distribution.)
GPD is similar to the Burr distribution.
Generating generalized Pareto random variables[]
Generating GPD random variables[]
If U is uniformly distributed on
(0, 1], then
and
Both formulas are obtained by inversion of the cdf.
In Matlab Statistics Toolbox, you can easily use "gprnd" command to generate generalized Pareto random numbers.
GPD as an Exponential-Gamma Mixture[]
A GPD random variable can also be expressed as an exponential random variable, with a Gamma distributed rate parameter.
and
then
Notice however, that since the parameters for the Gamma distribution must be greater than zero, we obtain the additional restrictions that: must be positive.
Exponentiated generalized Pareto distribution[]
The exponentiated generalized Pareto distribution (exGPD)[]
The pdf of the (exponentiated generalized Pareto distribution) for different values and .
See the right panel for the variance as a function of . Note that .
Note that the roles of the scale parameter and the shape parameter under are separably interpretable, which may lead to a robust efficient estimation for the than using the [2]. The roles of the two parameters are associated each other under (at least up to the second central moment); see the formula of variance wherein both parameters are participated.
The Hill's estimator[]
Assume that are observations (not need to be i.i.d.) from an unknown heavy-tailed distribution such that its tail distribution is regularly varying with the tail-index (hence, the corresponding shape parameter is ). To be specific, the tail distribution is described as
It is of a particular interest in the extreme value theory to estimate the shape parameter , especially when is positive (so called the heavy-tailed distribution).
Let be their conditional excess distribution function. Pickands–Balkema–de Haan theorem (Pickands, 1975; Balkema and de Haan, 1974) states that for a large class of underlying distribution functions , and large , is well approximated by the generalized Pareto distribution (GPD), which motivated Peak Over Threshold (POT) methods to estimate : the GPD plays the key role in POT approach.
A renowned estimator using the POT methodology is the Hill's estimator. Technical formulation of the Hill's estimator is as follows. For , write for the -th largest value of . Then, with this notation, the Hill's estimator (see page 190 of Reference 5 by Embrechts et al [3]) based on the upper order statistics is defined as
In practice, the Hill estimator is used as follows. First, calculate the estimator at each integer , and then plot the ordered pairs . Then, select from the set of Hill estimators which are roughly constant with respect to : these stable values are regarded as reasonable estimates for the shape parameter . If are i.i.d., then the Hill's estimator is a consistent estimator for the shape parameter [4].
Note that the Hill estimator makes a use of the log-transformation for the observations . (The Pickand's estimator also employed the log-transformation, but in a slightly different way
[5].)
^Dargahi-Noubary, G. R. (1989). "On tail estimation: An improved method". Mathematical Geology. 21 (8): 829–842. doi:10.1007/BF00894450. S2CID122710961.
^Hosking, J. R. M.; Wallis, J. R. (1987). "Parameter and Quantile Estimation for the Generalized Pareto Distribution". Technometrics. 29 (3): 339–349. doi:10.2307/1269343. JSTOR1269343.
Lee, Seyoon; Kim, J.H.K. (2018). "Exponentiated generalized Pareto distribution:Properties and applications towards extreme value theory". Communications in Statistics - Theory and Methods. 48 (8): 1–25. arXiv:1708.01686. doi:10.1080/03610926.2018.1441418. S2CID88514574.
N. L. Johnson; S. Kotz; N. Balakrishnan (1994). Continuous Univariate Distributions Volume 1, second edition. New York: Wiley. ISBN978-0-471-58495-7. Chapter 20, Section 12: Generalized Pareto Distributions.
Arnold, B. C.; Laguna, L. (1977). On generalized Pareto distributions with applications to income data. Ames, Iowa: Iowa State University, Department of Economics.


















![{\displaystyle e^{\theta \mu }\,\sum _{j=0}^{\infty }\left[{\frac {(\theta \sigma )^{j}}{\prod _{k=0}^{j}(1-k\xi )}}\right],\;(k\xi <1)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/41cf9f358ac58dcba4130cba492879256576e783)
![{\displaystyle e^{it\mu }\,\sum _{j=0}^{\infty }\left[{\frac {(it\sigma )^{j}}{\prod _{k=0}^{j}(1-k\xi )}}\right],\;(k\xi <1)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/53bfef161abce3834ebc5908620389e3174d612f)
![{\displaystyle \xi ={\frac {1}{2}}\left(1-{\frac {(E[X]-\mu )^{2}}{V[X]}}\right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/029894dab6a61a875e17d8ee5f27c7fe52dc4a89)
![{\displaystyle \sigma =(E[X]-\mu )(1-\xi )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7ae5aff7c32202ca44e85df4abac26bc3e6deb14)



















































![{\displaystyle M_{Y}(s)=E[e^{sY}]={\begin{cases}-{\frac {1}{\xi }}{\bigg (}-{\frac {\sigma }{\xi }}{\bigg )}^{s}B(s+1,-1/\xi )\,\,\,\,\,\,\,\,\,\,\,\,{\text{for }}s\in (-1,\infty ),\xi <0,\\{\frac {1}{\xi }}{\bigg (}{\frac {\sigma }{\xi }}{\bigg )}^{s}B(s+1,1/\xi -s)\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,{\text{for }}s\in (-1,1/\xi ),\xi >0,\\\sigma ^{s}\Gamma (1+s)\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,{\text{for }}s\in (-1,\infty ),\xi =0,\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/28884f7453a08deb806e6dcfadd72715427ba40b)


![{\displaystyle E[Y]={\begin{cases}\log \ {\bigg (}-{\frac {\sigma }{\xi }}{\bigg )}+\psi (1)-\psi (-1/\xi +1)\,\,\,\,\,\,\,\,\,\,\,\,\,\,{\text{for }}\xi <0,\\\log \ {\bigg (}{\frac {\sigma }{\xi }}{\bigg )}+\psi (1)-\psi (1/\xi )\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,{\text{for }}\xi >0,\\\log \sigma +\psi (1)\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,{\text{for }}\xi =0.\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a8417be06df13f42af281e304598ef2e687d03b5)


![{\displaystyle Var[Y]={\begin{cases}\psi '(1)-\psi '(-1/\xi +1)\,\,\,\,\,\,\,\,\,\,\,\,\,{\text{for }}\xi <0,\\\psi '(1)+\psi '(1/\xi )\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,{\text{for }}\xi >0,\\\psi '(1)\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,{\text{for }}\xi =0.\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b3d91dba75f48dfd9845bc57efdc32455bacac8a)





















