Zipf's law
|
Probability mass function 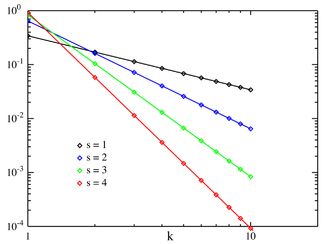 Zipf PMF for N = 10 on a log–log scale. The horizontal axis is the index k . (Note that the function is only defined at integer values of k. The connecting lines do not indicate continuity.) | |||
|
Cumulative distribution function 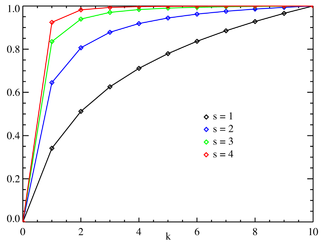 Zipf CDF for N = 10. The horizontal axis is the index k . (Note that the function is only defined at integer values of k. The connecting lines do not indicate continuity.) | |||
| Parameters |
(real) (integer) | ||
|---|---|---|---|
| Support | |||
| PMF | where HN,s is the Nth generalized harmonic number | ||
| CDF | |||
| Mean | |||
| Mode | |||
| Variance | |||
| Entropy | |||
| MGF | |||
| CF | |||











Zipf's law (/zɪf/, not /tsɪpf/ as in German) is an empirical law formulated using mathematical statistics that refers to the fact that for many types of data studied in the physical and social sciences, the rank-frequency distribution is an inverse relation. The Zipfian distribution is one of a family of related discrete power law probability distributions. It is related to the zeta distribution, but is not identical.
Zipf's law was originally formulated in terms of quantitative linguistics, stating that given some corpus of natural language utterances, the frequency of any word is inversely proportional to its rank in the frequency table. Thus the most frequent word will occur approximately twice as often as the second most frequent word, three times as often as the third most frequent word, etc. For example, in the Brown Corpus of American English text, the word "the" is the most frequently occurring word, and by itself accounts for nearly 7% of all word occurrences (69,971 out of slightly over 1 million). True to Zipf's Law, the second-place word "of" accounts for slightly over 3.5% of words (36,411 occurrences), followed by "and" (28,852). Only 135 vocabulary items are needed to account for half the Brown Corpus.[1]
The law is named after the American linguist George Kingsley Zipf (1902–1950), who popularized it and sought to explain it (Zipf 1935, 1949), though he did not claim to have originated it.[2] The French stenographer Jean-Baptiste Estoup (1868–1950) appears to have noticed the regularity before Zipf.[3] It was also noted in 1913 by German physicist Felix Auerbach (1856–1933).[4]
The law is similar in concept, though not identical in distribution, to Benford's law.
Other data sets[]
The same relationship occurs in many other rankings of human-created systems,[5] such as the ranks of mathematical expressions or ranks of notes in music[6] and even in uncontrolled environments, such as the population ranks of cities in various countries, corporation sizes, income rankings, ranks of number of people watching the same TV channel,[7] cells' transcriptomes[8] and so on. The appearance of the distribution in rankings of cities by population was first noticed by Felix Auerbach in 1913.[4] Empirically, a data set can be tested to see whether Zipf's law applies by checking the goodness of fit of an empirical distribution to the hypothesized power law distribution with a Kolmogorov–Smirnov test, and then comparing the (log) likelihood ratio of the power law distribution to alternative distributions like an exponential distribution or lognormal distribution.[9]
When Zipf's law is checked for cities, a better fit has been found with exponent s = 1.07; i.e. the n-th largest settlement is the size of the largest settlement, in other words: as according to Zipf's law.



Theoretical review[]
Zipf's law is most easily observed by plotting the data on a log-log graph, with the axes being log (rank order) and log (frequency). For example, the word "the" (as described above) would appear at x = log(1), y = log(69971). It is also possible to plot reciprocal rank against frequency or reciprocal frequency or interword interval against rank.[2] The data conform to Zipf's law to the extent that the plot is linear.
Formally, let:
- N be the number of elements;
- k be their rank;
- s be the value of the exponent characterizing the distribution.
Zipf's law then predicts that out of a population of N elements, the normalized frequency of the element of rank k, f(k;s,N), is:

Zipf's law holds if the number of elements with a given frequency is a random variable with power law distribution [10]

It has been claimed that this representation of Zipf's law is more suitable for statistical testing, and in this way it has been analyzed in more than 30,000 English texts. The goodness-of-fit tests yield that only about 15% of the texts are statistically compatible with this form of Zipf's law. Slight variations in the definition of Zipf's law can increase this percentage up to close to 50%.[11]
In the example of the frequency of words in the English language, N is the number of words in the English language and, if we use the classic version of Zipf's law, the exponent s is 1. f(k; s,N) will then be the fraction of the time the kth most common word occurs.
The law may also be written:

where HN,s is the Nth generalized harmonic number.
The simplest case of Zipf's law is a "1/f" function. Given a set of Zipfian distributed frequencies, sorted from most common to least common, the second most common frequency will occur half as often as the first, the third most common frequency will occur 1/3 as often as the first, and the nth most common frequency will occur 1/n as often as the first. However, this cannot hold exactly, because items must occur an integer number of times; there cannot be 2.5 occurrences of a word. Nevertheless, over fairly wide ranges, and to a fairly good approximation, many natural phenomena obey Zipf's law.
In human languages, word frequencies have a very heavy-tailed distribution, and can therefore be modeled reasonably well by a Zipf distribution with an s close to 1.
As long as the exponent s exceeds 1, it is possible for such a law to hold with infinitely many words, since if s > 1 then

where ζ is Riemann's zeta function.
Statistical explanation[]

Although Zipf's Law holds for all languages, even non-natural ones like Esperanto,[12] the reason is still not well understood.[13] However, it may be partially explained by the statistical analysis of randomly generated texts. Wentian Li has shown that in a document in which each character has been chosen randomly from a uniform distribution of all letters (plus a space character), the "words" with different lengths follow the macro-trend of the Zipf's law (the more probable words are the shortest with equal probability).[14] Vitold Belevitch, in a paper entitled On the Statistical Laws of Linguistic Distribution, offers a mathematical derivation. He took a large class of well-behaved statistical distributions (not only the normal distribution) and expressed them in terms of rank. He then expanded each expression into a Taylor series. In every case Belevitch obtained the remarkable result that a first-order truncation of the series resulted in Zipf's law. Further, a second-order truncation of the Taylor series resulted in Mandelbrot's law.[15][16]
The principle of least effort is another possible explanation: Zipf himself proposed that neither speakers nor hearers using a given language want to work any harder than necessary to reach understanding, and the process that results in approximately equal distribution of effort leads to the observed Zipf distribution.[17][18]
Similarly, preferential attachment (intuitively, "the rich get richer" or "success breeds success") that results in the Yule–Simon distribution has been shown to fit word frequency versus rank in language[19] and population versus city rank[20] better than Zipf's law. It was originally derived to explain population versus rank in species by Yule, and applied to cities by Simon.
Mathematical explanation[]
Atlas models are systems of exchangeable positive-valued diffusion processes with drift and variance parameters that depend only on the rank of the process. It has been shown mathematically that Zipf's law holds for Atlas models that satisfy certain natural regularity conditions.[21] Atlas models can be used to represent empirical systems of time-dependent multivariate data, including, e.g., the frequency of words in a written language, the population of cities, and the size of companies. An Atlas model that represents an empirical system will have the same stationary distribution as the empirical system, so if the Atlas model follows Zipf's law, the system will also follow Zipf's law. Since Atlas models that satisfy natural regularity conditions follow Zipf's law, this accounts for its universality.[22]
In the figure above of the 10 million Wikipedia words, the log-log plots are not precisely straight lines but rather slightly concave curves with a tangent of slope -1 at some point along the curve. Such distributions are usually referred to as quasi-Zipfian distributions, and most systems of time-dependent empirical data that are said to follow Zipf's law are actually quasi-Zipfian. Quasi-Zipfian systems can be represented by quasi-Atlas models, and quasi-Atlas models are amenable to mathematical treatment similar to that for Zipf's law.
Related laws[]

Zipf's law in fact refers more generally to frequency distributions of "rank data", in which the relative frequency of the nth-ranked item is given by the zeta distribution, 1/(nsζ(s)), where the parameter s > 1 indexes the members of this family of probability distributions. Indeed, Zipf's law is sometimes synonymous with "zeta distribution", since probability distributions are sometimes called "laws". This distribution is sometimes called the Zipfian distribution.
A generalization of Zipf's law is the Zipf–Mandelbrot law, proposed by Benoit Mandelbrot, whose frequencies are:
![{\displaystyle f(k;N,q,s)={\frac {[{\text{constant}}]}{(k+q)^{s}}}.\,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fa491882940976898252010592e6c19ce6092ba9)
The "constant" is the reciprocal of the Hurwitz zeta function evaluated at s. In practice, as easily observable in distribution plots for large corpora, the observed distribution can be modelled more accurately as a sum of separate distributions for different subsets or subtypes of words that follow different parameterizations of the Zipf–Mandelbrot distribution, in particular the closed class of functional words exhibit s lower than 1, while open-ended vocabulary growth with document size and corpus size require s greater than 1 for convergence of the Generalized Harmonic Series.[2]
Zipfian distributions can be obtained from Pareto distributions by an exchange of variables.[10]
The Zipf distribution is sometimes called the discrete Pareto distribution[23] because it is analogous to the continuous Pareto distribution in the same way that the discrete uniform distribution is analogous to the continuous uniform distribution.
The tail frequencies of the Yule–Simon distribution are approximately
![{\displaystyle f(k;\rho )\approx {\frac {[{\text{constant}}]}{k^{\rho +1}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/78fb2a5a8523f03c5e11716e40fd9627c18ff49f)
for any choice of ρ > 0.
In the parabolic fractal distribution, the logarithm of the frequency is a quadratic polynomial of the logarithm of the rank. This can markedly improve the fit over a simple power-law relationship.[24] Like fractal dimension, it is possible to calculate Zipf dimension, which is a useful parameter in the analysis of texts.[25]
It has been argued that Benford's law is a special bounded case of Zipf's law,[24] with the connection between these two laws being explained by their both originating from scale invariant functional relations from statistical physics and critical phenomena.[26] The ratios of probabilities in Benford's law are not constant. The leading digits of data satisfying Zipf's law with s = 1 satisfy Benford's law.
| Benford's law: |
||
|---|---|---|
| 1 | 0.30103000 | |
| 2 | 0.17609126 | −0.7735840 |
| 3 | 0.12493874 | −0.8463832 |
| 4 | 0.09691001 | −0.8830605 |
| 5 | 0.07918125 | −0.9054412 |
| 6 | 0.06694679 | −0.9205788 |
| 7 | 0.05799195 | −0.9315169 |
| 8 | 0.05115252 | −0.9397966 |
| 9 | 0.04575749 | −0.9462848 |




Applications[]
In information theory, a symbol (event, signal) of probability contains bits of information. Hence, Zipf's law for natural numbers: is equivalent with number containing bits of information. To add information from a symbol of probability into information already stored in a natural number , we should go to such that , or equivalently . For instance, in standard binary system we would have , what is optimal for probability distribution. Using rule for a general probability distribution is the base of Asymmetric Numeral Systems family of entropy coding methods used in data compression, whose state distribution is also governed by Zipf's law.










Zipf's law has been used for extraction of parallel fragments of texts out of comparable corpora.[27] Zipf's law has also been used by Laurance Doyle and others at the SETI Institute as part of the search for extraterrestrial intelligence.[28][29]
See also[]
- 1% rule (Internet culture)
- Benford's law
- Bradford's law
- Brevity law
- Demographic gravitation
- Frequency list
- Gibrat's law
- Hapax legomenon
- Heaps' law
- King effect
- Lorenz curve
- Lotka's law
- Menzerath's law
- Pareto distribution
- Pareto principle, a.k.a. the "80–20 rule"
- Price's law
- Principle of least effort
- Rank-size distribution
- Stigler's law of eponymy
- Long tail
References[]
- ^ Fagan, Stephen; Gençay, Ramazan (2010), "An introduction to textual econometrics", in Ullah, Aman; Giles, David E. A. (eds.), Handbook of Empirical Economics and Finance, CRC Press, pp. 133–153, ISBN 9781420070361. P. 139: "For example, in the Brown Corpus, consisting of over one million words, half of the word volume consists of repeated uses of only 135 words."
- ^ Jump up to: a b c Powers, David M W (1998). Applications and explanations of Zipf's law. Joint conference on new methods in language processing and computational natural language learning. Association for Computational Linguistics. pp. 151–160.
- ^ Christopher D. Manning, Hinrich Schütze Foundations of Statistical Natural Language Processing, MIT Press (1999), ISBN 978-0-262-13360-9, p. 24
- ^ Jump up to: a b Auerbach F. (1913) Das Gesetz der Bevölkerungskonzentration. Petermann’s Geographische Mitteilungen 59, 74–76
- ^ Piantadosi, Steven (March 25, 2014). "Zipf's word frequency law in natural language: A critical review and future directions". Psychon Bull Rev. 21 (5): 1112–1130. doi:10.3758/s13423-014-0585-6. PMC 4176592. PMID 24664880.
- ^ Zanette, Damián H. (June 7, 2004). "Zipf's law and the creation of musical context". arXiv:cs/0406015.
- ^ M. Eriksson, S.M. Hasibur Rahman, F. Fraille, M. Sjöström, Efficient Interactive Multicast over DVB-T2 - Utilizing Dynamic SFNs and PARPS Archived 2014-05-02 at the Wayback Machine, 2013 IEEE International Conference on Computer and Information Technology (BMSB'13), London, UK, June 2013. Suggests a heterogeneous Zipf-law TV channel-selection model
- ^ Lazzardi, Silvia; Valle, Filippo; Mazzolini, Andrea; Scialdone, Antonio; Caselle, Michele; Osella, Matteo (2021-06-17). "Emergent Statistical Laws in Single-Cell Transcriptomic Data". bioRxiv: 2021–06.16.448706. doi:10.1101/2021.06.16.448706. S2CID 235482777. Retrieved 2021-06-18.
- ^ Clauset, A., Shalizi, C. R., & Newman, M. E. J. (2009). Power-Law Distributions in Empirical Data. SIAM Review, 51(4), 661–703. doi:10.1137/070710111
- ^ Jump up to: a b Adamic, Lada A. (2000) "Zipf, Power-laws, and Pareto - a ranking tutorial", originally published at .parc.xerox.com Archived 2007-10-26 at the Wayback Machine
- ^ Moreno-Sánchez, I; Font-Clos, F; Corral, A (2016). "Large-Scale Analysis of Zipf's Law in English Texts". PLOS ONE. 11 (1): e0147073. arXiv:1509.04486. Bibcode:2016PLoSO..1147073M. doi:10.1371/journal.pone.0147073. PMC 4723055. PMID 26800025.
- ^ Bill Manaris; Luca Pellicoro; George Pothering; Harland Hodges (13 February 2006). Investigating Esperanto's statistical proportions relative to other languages using neural networks and Zipf's law (PDF). . Innsbruck, Austria. pp. 102–108. Archived from the original (PDF) on 5 March 2016.
- ^ Léon Brillouin, La science et la théorie de l'information, 1959, réédité en 1988, traduction anglaise rééditée en 2004
- ^ Wentian Li (1992). "Random Texts Exhibit Zipf's-Law-Like Word Frequency Distribution". IEEE Transactions on Information Theory. 38 (6): 1842–1845. CiteSeerX 10.1.1.164.8422. doi:10.1109/18.165464.
- ^ Neumann, Peter G. "Statistical metalinguistics and Zipf/Pareto/Mandelbrot", SRI International Computer Science Laboratory, accessed and archived 29 May 2011.
- ^ Belevitch V (18 December 1959). "On the statistical laws of linguistic distributions" (PDF). Annales de la Société Scientifique de Bruxelles. I. 73: 310–326.
- ^ Zipf GK (1949). Human Behavior and the Principle of Least Effort. Cambridge, Massachusetts: Addison-Wesley. p. 1.
- ^ Ramon Ferrer i Cancho & Ricard V. Sole (2003). "Least effort and the origins of scaling in human language". Proceedings of the National Academy of Sciences of the United States of America. 100 (3): 788–791. Bibcode:2003PNAS..100..788C. doi:10.1073/pnas.0335980100. PMC 298679. PMID 12540826.
- ^ Lin, Ruokuang; Ma, Qianli D. Y.; Bian, Chunhua (2014). "Scaling laws in human speech, decreasing emergence of new words and a generalized model". arXiv:1412.4846 [cs.CL].
- ^ Vitanov, Nikolay K.; Ausloos, Marcel; Bian, Chunhua (2015). "Test of two hypotheses explaining the size of populations in a system of cities". Journal of Applied Statistics. 42 (12): 2686–2693. arXiv:1506.08535. Bibcode:2015arXiv150608535V. doi:10.1080/02664763.2015.1047744. S2CID 10599428.
- ^ Ricardo T. Fernholz; Robert Fernholz (December 2020). "Zipf's law for atlas models". Journal of Applied Probability. 57 (4): 1276–1297. doi:10.1017/jpr.2020.64. S2CID 146808080.
- ^ Terence Tao (2012). "E Pluribus Unum: From Complexity, Universality". Daedalus. 141 (3): 23–34. doi:10.1162/DAED_a_00158. S2CID 14535989.
- ^ N. L. Johnson; S. Kotz & A. W. Kemp (1992). Univariate Discrete Distributions (second ed.). New York: John Wiley & Sons, Inc. ISBN 978-0-471-54897-3., p. 466.
- ^ Jump up to: a b Johan Gerard van der Galien (2003-11-08). "Factorial randomness: the Laws of Benford and Zipf with respect to the first digit distribution of the factor sequence from the natural numbers". Archived from the original on 2007-03-05. Retrieved 8 July 2016.
- ^ Eftekhari, Ali (2006). "Fractal geometry of texts: An initial application to the works of Shakespeare". Journal of Quantitative Linguistic. 13 (2–3): 177–193. doi:10.1080/09296170600850106. S2CID 17657731.
- ^ Pietronero, L.; Tosatti, E.; Tosatti, V.; Vespignani, A. (2001). "Explaining the uneven distribution of numbers in nature: The laws of Benford and Zipf". Physica A. 293 (1–2): 297–304. Bibcode:2001PhyA..293..297P. doi:10.1016/S0378-4371(00)00633-6.
- ^ Mohammadi, Mehdi (2016). "Parallel Document Identification using Zipf's Law" (PDF). Proceedings of the Ninth Workshop on Building and Using Comparable Corpora. LREC 2016. Portorož, Slovenia. pp. 21–25. Archived (PDF) from the original on 2018-03-23.
- ^ Doyle, Laurance R.; Mao, Tianhua (2016-11-18). "Why Alien Language Would Stand Out Among All the Noise of the Universe". Nautilus Quarterly.
- ^ Kershenbaum, Arik (2021-03-16). The Zoologist's Guide to the Galaxy: What Animals on Earth Reveal About Aliens--and Ourselves. Penguin. pp. 251–256. ISBN 978-1-9848-8197-7. OCLC 1242873084.
Further reading[]
Primary:
- George K. Zipf (1949) Human Behavior and the Principle of Least Effort. Addison-Wesley. "Online text [1]"
- George K. Zipf (1935) The Psychobiology of Language. Houghton-Mifflin.
Secondary:
- Alexander Gelbukh and Grigori Sidorov (2001) "Zipf and Heaps Laws’ Coefficients Depend on Language". Proc. CICLing-2001, Conference on Intelligent Text Processing and Computational Linguistics, February 18–24, 2001, Mexico City. Lecture Notes in Computer Science N 2004, ISSN 0302-9743, ISBN 3-540-41687-0, Springer-Verlag: 332–335.
- Damián H. Zanette (2006) "Zipf's law and the creation of musical context," Musicae Scientiae 10: 3–18.
- Frans J. Van Droogenbroeck (2016), Handling the Zipf distribution in computerized authorship attribution
- Frans J. Van Droogenbroeck (2019), An essential rephrasing of the Zipf-Mandelbrot law to solve authorship attribution applications by Gaussian statistics
- Kali R. (2003) "The city as a giant component: a random graph approach to Zipf's law," Applied Economics Letters 10: 717–720(4)
- Gabaix, Xavier (August 1999). "Zipf's Law for Cities: An Explanation" (PDF). Quarterly Journal of Economics. 114 (3): 739–67. CiteSeerX 10.1.1.180.4097. doi:10.1162/003355399556133. ISSN 0033-5533.
- Axtell, Robert L; Zipf distribution of US firm sizes, Science, 293, 5536, 1818, 2001, American Association for the Advancement of Science
- Ramu Chenna, Toby Gibson; Evaluation of the Suitability of a Zipfian Gap Model for Pairwise Sequence Alignment, International Conference on Bioinformatics Computational Biology: 2011.
- Shyklo A. (2017); Simple Explanation of Zipf's Mystery via New Rank-Share Distribution, Derived from Combinatorics of the Ranking Process, Available at SSRN: https://ssrn.com/abstract=2918642.
External links[]
| Library resources about Zipf's law |
| Wikimedia Commons has media related to Zipf's law. |
- Strogatz, Steven (2009-05-29). "Guest Column: Math and the City". The New York Times. Retrieved 2009-05-29.—An article on Zipf's law applied to city populations
- Seeing Around Corners (Artificial societies turn up Zipf's law)
- PlanetMath article on Zipf's law
- Distributions de type "fractal parabolique" dans la Nature (French, with English summary)
- An analysis of income distribution
- Zipf List of French words
- Zipf list for English, French, Spanish, Italian, Swedish, Icelandic, Latin, Portuguese and Finnish from Gutenberg Project and online calculator to rank words in texts
- Citations and the Zipf–Mandelbrot's law
- Zipf's Law examples and modelling (1985)
- Complex systems: Unzipping Zipf's law (2011)
- Benford’s law, Zipf’s law, and the Pareto distribution by Terence Tao.
- "Zipf law", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
| show Authority control |
|---|
- Discrete distributions
- Computational linguistics
- Power laws
- Statistical laws
- Empirical laws
- Tails of probability distributions
- Quantitative linguistics
- Bibliometrics
- Corpus linguistics
- 1949 introductions