AlexNet
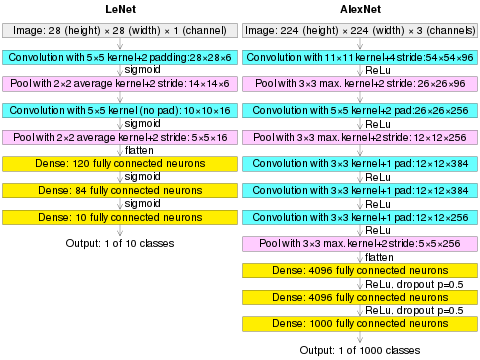
AlexNet is the name of a convolutional neural network (CNN) architecture, designed by Alex Krizhevsky in collaboration with Ilya Sutskever and Geoffrey Hinton, who was Krizhevsky's Ph.D. advisor.[1][2]
AlexNet competed in the ImageNet Large Scale Visual Recognition Challenge on September 30, 2012.[3] The network achieved a top-5 error of 15.3%, more than 10.8 percentage points lower than that of the runner up. The original paper's primary result was that the depth of the model was essential for its high performance, which was computationally expensive, but made feasible due to the utilization of graphics processing units (GPUs) during training.[2]
Historic context[]
AlexNet was not the first fast GPU-implementation of a CNN to win an image recognition contest. A CNN on GPU by K. Chellapilla et al. (2006) was 4 times faster than an equivalent implementation on CPU.[4] A deep CNN of Dan Cireșan et al. (2011) at IDSIA was already 60 times faster[5] and achieved superhuman performance in August 2011.[6] Between May 15, 2011 and September 10, 2012, their CNN won no fewer than four image competitions.[7][8] They also significantly improved on the best performance in the literature for multiple image databases.[9]
According to the AlexNet paper,[2] Cireșan's earlier net is "somewhat similar." Both were originally written with CUDA to run with GPU support. In fact, both are actually just variants of the CNN designs introduced by Yann LeCun et al. (1989)[10][11] who applied the backpropagation algorithm to a variant of Kunihiko Fukushima's original CNN architecture called "neocognitron."[12][13] The architecture was later modified by J. Weng's method called max-pooling.[14][8]
In 2015, AlexNet was outperformed by Microsoft Research Asia's very deep CNN with over 100 layers, which won the ImageNet 2015 contest.[15]
Network design[]
AlexNet contained eight layers; the first five were convolutional layers, some of them followed by max-pooling layers, and the last three were fully connected layers.[2] It used the non-saturating ReLU activation function, which showed improved training performance over tanh and sigmoid.[2]
Influence[]
AlexNet is considered one of the most influential papers published in computer vision, having spurred many more papers published employing CNNs and GPUs to accelerate deep learning.[16] As of 2021, the AlexNet paper has been cited over 80,000 times according to Google Scholar.
References[]
- ^ "The data that transformed AI research—and possibly the world".
- ^ Jump up to: a b c d e Krizhevsky, Alex; Sutskever, Ilya; Hinton, Geoffrey E. (2017-05-24). "ImageNet classification with deep convolutional neural networks" (PDF). Communications of the ACM. 60 (6): 84–90. doi:10.1145/3065386. ISSN 0001-0782. S2CID 195908774.
- ^ "ILSVRC2012 Results".
- ^ Kumar Chellapilla; Sid Puri; Patrice Simard (2006). "High Performance Convolutional Neural Networks for Document Processing". In Lorette, Guy (ed.). Tenth International Workshop on Frontiers in Handwriting Recognition. Suvisoft.
- ^ Cireșan, Dan; Ueli Meier; Jonathan Masci; Luca M. Gambardella; Jurgen Schmidhuber (2011). "Flexible, High Performance Convolutional Neural Networks for Image Classification" (PDF). Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence-Volume Volume Two. 2: 1237–1242. Retrieved 17 November 2013.
- ^ "IJCNN 2011 Competition result table". OFFICIAL IJCNN2011 COMPETITION. 2010. Retrieved 2019-01-14.
- ^ Schmidhuber, Jürgen (17 March 2017). "History of computer vision contests won by deep CNNs on GPU". Retrieved 14 January 2019.
- ^ Jump up to: a b Schmidhuber, Jürgen (2015). "Deep Learning". Scholarpedia. 10 (11): 1527–54. CiteSeerX 10.1.1.76.1541. doi:10.1162/neco.2006.18.7.1527. PMID 16764513. S2CID 2309950.
- ^ Cireșan, Dan; Meier, Ueli; Schmidhuber, Jürgen (June 2012). Multi-column deep neural networks for image classification. 2012 IEEE Conference on Computer Vision and Pattern Recognition. New York, NY: Institute of Electrical and Electronics Engineers (IEEE). pp. 3642–3649. arXiv:1202.2745. CiteSeerX 10.1.1.300.3283. doi:10.1109/CVPR.2012.6248110. ISBN 978-1-4673-1226-4. OCLC 812295155. S2CID 2161592.
- ^ LeCun, Y.; Boser, B.; Denker, J. S.; Henderson, D.; Howard, R. E.; Hubbard, W.; Jackel, L. D. (1989). "Backpropagation Applied to Handwritten Zip Code Recognition" (PDF). Neural Computation. MIT Press - Journals. 1 (4): 541–551. doi:10.1162/neco.1989.1.4.541. ISSN 0899-7667. OCLC 364746139.
- ^ LeCun, Yann; Léon Bottou; Yoshua Bengio; Patrick Haffner (1998). "Gradient-based learning applied to document recognition" (PDF). Proceedings of the IEEE. 86 (11): 2278–2324. CiteSeerX 10.1.1.32.9552. doi:10.1109/5.726791. Retrieved October 7, 2016.
- ^ Fukushima, K. (2007). "Neocognitron". Scholarpedia. 2 (1): 1717. Bibcode:2007SchpJ...2.1717F. doi:10.4249/scholarpedia.1717.
- ^ Fukushima, Kunihiko (1980). "Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position" (PDF). Biological Cybernetics. 36 (4): 193–202. doi:10.1007/BF00344251. PMID 7370364. S2CID 206775608. Retrieved 16 November 2013.
- ^ Weng, J; Ahuja, N; Huang, TS (1993). "Learning recognition and segmentation of 3-D objects from 2-D images". Proc. 4th International Conf. Computer Vision: 121–128.
- ^ He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian (2016). "Deep Residual Learning for Image Recognition". 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR): 770–778. arXiv:1512.03385. doi:10.1109/CVPR.2016.90. ISBN 978-1-4673-8851-1. S2CID 206594692.
- ^ Deshpande, Adit. "The 9 Deep Learning Papers You Need To Know About (Understanding CNNs Part 3)". adeshpande3.github.io. Retrieved 2018-12-04.
| hide Differentiable computing | |||||||
|---|---|---|---|---|---|---|---|
| General |  | ||||||
| Concepts | |||||||
| Programming languages | |||||||
| Application | |||||||
| Hardware | |||||||
| Software library | |||||||
| Implementation |
| ||||||
| People | |||||||
| Organizations | |||||||
| |||||||
This programming-tool-related article is a stub. You can help Wikipedia by . |
- Neural network software
- Deep learning
- Artificial neural networks
- Object recognition and categorization
- Computer programming tool stubs