Data augmentation
This article relies largely or entirely on a single source. (September 2020) |
Data augmentation in data analysis are techniques used to increase the amount of data by adding slightly modified copies of already existing data or newly created synthetic data from existing data. It acts as a regularizer and helps reduce overfitting when training a machine learning model.[1] It is closely related to oversampling in data analysis.
Synthetic oversampling techniques for traditional machine learning[]
Data augmentation for image classification[]
Transformations of images[]

Geometric transformations, flipping, color modification, cropping, rotation, noise injection and random erasing are used to augment image in deep learning.[1]
Introducing new synthetic images[]
If a dataset is very small, then a version augmented with rotation and mirroring etc. may still not be enough for a given problem. Another solution is the sourcing of entirely new, synthetic images through various techniques, for example the use of generative adversarial networks to create new synthetic images for data augmentation.[1] Additionally, image recognition algorithms show improvement when transferring from images rendered in virtual environments to real-world data.[3]
Data augmentation for signal processing[]
Residual or block bootstrap can be used for time series augmentation.
Biological signals[]
Synthetic data augmentation is of paramount importance for machine learning classification, particularly for biological data, which tend to be high dimensional and scarce. The applications of robotic control and augmentation in disabled and able-bodied subjects still rely mainly on subject-specific analyses. Data scarcity is notable in signal processing problems such as for Parkinson's Disease Electromyography signals, which are difficult to source - Zanini, et al. noted that it is possible to use a Generative adversarial network (in particular, a DCGAN) to perform style transfer in order to generate synthetic electromyographic signals that corresponded to those exhibited by sufferers of Parkinson's Disease.[4]
The approaches are also important in electroencephalography (brainwaves). Wang, et al. explored the idea of using Deep for EEG-Based Emotion Recognition, results show that emotion recognition was improved when data augmentation was used.[5]
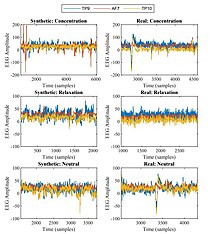
It has also been noted that OpenAI's GPT-2 model is capable of learning from, and generating synthetic biological signals such as EEG and EMG.[6] In this study, it was noted that recognition was improved via data augmentation. It was also noted that statistical machine learning models trained on the synthetic domain could classify the human data, and vice versa. In the image, a comparison is given by some examples of EEG produced by the GPT-2 model and a human brain.
A common approach is to generate synthetic signals by re-arranging components of real data. Lotte[7] proposed a method of "Artificial Trial Generation Based on Analogy" where three data examples provide examples and an artificial is formed which is to what is to . A transformation is applied to to make it more similar to , the same transformation is then applied to which generates . This approach was shown to improve performance of a Linear Discriminant Analysis classifier on three different datasets.





Current research shows great impact can be derived from relatively simple techniques. For example, Freer[8] observed that introducing noise into gathered data to form additional data points improved the learning ability of several models which otherwise performed relatively poorly. Tsinganos et al.[9] studied the approaches of magnitude warping, wavelet decomposition, and synthetic surface EMG models (generative approaches) for hand gesture recognition, finding classification performance increases of up to +16% when augmented data was introduced during training. More recently, data augmentation studies have begun to focus on the field of deep learning, more specifically on the ability of generative models to create artificial data which is then introduced during the classification model training process. In 2018, Luo et al.[10] observed that useful EEG signal data could be generated by Conditional Wasserstein Generative Adversarial Networks (GANs) which was then introduced to the training set in a classical train-test learning framework. The authors found classification performance was improved when such techniques were introduced.
Data augmentation for speech recognition[]
It has been noted that synthetic data generation of spoken MFCCs can improve the recognition of a speaker from their utterances via transfer learning from synthetic data which has been generated via a Character-level Recurrent Neural Network (RNN).[11]
See also[]
- Oversampling and undersampling in data analysis
- Generative adversarial network
- Variational autoencoder
- Data pre-processing
- Convolutional neural network
- Regularization (mathematics)
- Data preparation
- Data fusion
References[]
- ^ a b c Shorten, Connor; Khoshgoftaar, Taghi M. (2019). "A survey on Image Data Augmentation for Deep Learning". Mathematics and Computers in Simulation. springer. 6: 60. doi:10.1186/s40537-019-0197-0.
- ^ D Bloice, Marcus; Stocker, Christof; Holzinger, Andreas (2017). "Augmentor: An Image Augmentation Library for Machine Learning". The Journal of Open Source Software. 2 (19): 432. Bibcode:2017JOSS....2..432D. doi:10.21105/joss.00432. ISSN 2475-9066.
- ^ Bird, Jordan J; Faria, Diego R; Ekart, Aniko; Ayrosa, Pedro PS (2020-08-30). From simulation to reality: CNN transfer learning for scene classification. 2020 IEEE 10th International Conference on Intelligent Systems (IS). Varna, Bulgaria: IEEE. pp. 619–625.
{{cite conference}}: CS1 maint: date and year (link) - ^ Anicet Zanini, Rafael; Luna Colombini, Esther (2020). "Parkinson's Disease EMG Data Augmentation and Simulation with DCGANs and Style Transfer". Sensors. 20 (9): 2605. doi:10.3390/s20092605. ISSN 1424-8220. PMC 7248755. PMID 32375217.
- ^ Wang, Fang; Zhong, Sheng-hua; Peng, Jianfeng; Jiang, Jianmin; Liu, Yan (2018). "Data Augmentation for EEG-Based Emotion Recognition with Deep Convolutional Neural Networks". Multi Media Modeling. Lecture Notes in Computer Science. Vol. 10705. pp. 82–93. doi:10.1007/978-3-319-73600-6_8. ISBN 978-3-319-73599-3. ISSN 0302-9743.
- ^ a b Bird, Jordan J.; Pritchard, Michael George; Fratini, Antonio; Ekart, Aniko; Faria, Diego (2021). "Synthetic Biological Signals Machine-generated by GPT-2 improve the Classification of EEG and EMG through Data Augmentation" (PDF). IEEE Robotics and Automation Letters. 6 (2): 3498–3504. doi:10.1109/LRA.2021.3056355. ISSN 2377-3766. S2CID 232373183.
- ^ Lotte, Fabien (2015). "Signal Processing Approaches to Minimize or Suppress Calibration Time in Oscillatory Activity-Based Brain–Computer Interfaces". Proceedings of the IEEE. 103 (6): 871–890. doi:10.1109/JPROC.2015.2404941. ISSN 0018-9219. S2CID 22472204.
- ^ Freer, Daniel; Yang, Guang-Zhong (2020). "Data augmentation for self-paced motor imagery classification with C-LSTM". Journal of Neural Engineering. 17 (1): 016041. Bibcode:2020JNEng..17a6041F. doi:10.1088/1741-2552/ab57c0. hdl:10044/1/75376. ISSN 1741-2552. PMID 31726440.
- ^ Tsinganos, Panagiotis; Cornelis, Bruno; Cornelis, Jan; Jansen, Bart; Skodras, Athanassios (2020). "Data Augmentation of Surface Electromyography for Hand Gesture Recognition". Sensors. 20 (17): 4892. doi:10.3390/s20174892. ISSN 1424-8220. PMC 7506981. PMID 32872508.
- ^ Luo, Yun; Lu, Bao-Liang (2018). "EEG Data Augmentation for Emotion Recognition Using a Conditional Wasserstein GAN". 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). Annual International Conference of the IEEE Engineering in Medicine and Biology Society. IEEE Engineering in Medicine and Biology Society. Annual International Conference. Vol. 2018. pp. 2535–2538. doi:10.1109/EMBC.2018.8512865. ISBN 978-1-5386-3646-6. PMID 30440924. S2CID 53105445.
- ^ Bird, Jordan J.; Faria, Diego R.; Premebida, Cristiano; Ekart, Aniko; Ayrosa, Pedro P. S. (2020). "Overcoming Data Scarcity in Speaker Identification: Dataset Augmentation with Synthetic MFCCs via Character-level RNN". 2020 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC). pp. 146–151. doi:10.1109/ICARSC49921.2020.9096166. ISBN 978-1-7281-7078-7. S2CID 218832459.
Differentiable computing | |||||||
|---|---|---|---|---|---|---|---|
| General | |||||||
| Concepts | |||||||
| Programming languages | |||||||
| Application | |||||||
| Hardware | |||||||
| Software library | |||||||
| Implementation |
| ||||||
| People | |||||||
| Organizations | |||||||
| |||||||
- Machine learning