Automatic differentiation
In mathematics and computer algebra, automatic differentiation (AD), also called algorithmic differentiation, computational differentiation,[1][2] auto-differentiation, or simply autodiff, is a set of techniques to evaluate the derivative of a function specified by a computer program. AD exploits the fact that every computer program, no matter how complicated, executes a sequence of elementary arithmetic operations (addition, subtraction, multiplication, division, etc.) and elementary functions (exp, log, sin, cos, etc.). By applying the chain rule repeatedly to these operations, derivatives of arbitrary order can be computed automatically, accurately to working precision, and using at most a small constant factor more arithmetic operations than the original program.

Automatic differentiation is distinct from symbolic differentiation and numerical differentiation (the method of finite differences). Symbolic differentiation can lead to inefficient code and faces the difficulty of converting a computer program into a single expression, while numerical differentiation can introduce round-off errors in the discretization process and cancellation. Both classical methods have problems with calculating higher derivatives, where complexity and errors increase. Finally, both classical methods are slow at computing partial derivatives of a function with respect to many inputs, as is needed for gradient-based optimization algorithms. Automatic differentiation solves all of these problems.
The chain rule, forward and reverse accumulation[]
Fundamental to AD is the decomposition of differentials provided by the chain rule. For the simple composition


Usually, two distinct modes of AD are presented, forward accumulation (or forward mode) and reverse accumulation (or reverse mode). Forward accumulation specifies that one traverses the chain rule from inside to outside (that is, first compute and then and at last ), while reverse accumulation has the traversal from outside to inside (first compute and then and at last ). More succinctly,



- forward accumulation computes the recursive relation: with , and,
- reverse accumulation computes the recursive relation: with .




Forward accumulation[]
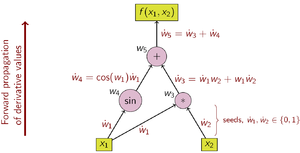
In forward accumulation AD, one first fixes the independent variable with respect to which differentiation is performed and computes the derivative of each sub-expression recursively. In a pen-and-paper calculation, this involves repeatedly substituting the derivative of the inner functions in the chain rule:
![{\displaystyle {\begin{aligned}{\frac {\partial y}{\partial x}}&={\frac {\partial y}{\partial w_{n-1}}}{\frac {\partial w_{n-1}}{\partial x}}\\[6pt]&={\frac {\partial y}{\partial w_{n-1}}}\left({\frac {\partial w_{n-1}}{\partial w_{n-2}}}{\frac {\partial w_{n-2}}{\partial x}}\right)\\[6pt]&={\frac {\partial y}{\partial w_{n-1}}}\left({\frac {\partial w_{n-1}}{\partial w_{n-2}}}\left({\frac {\partial w_{n-2}}{\partial w_{n-3}}}{\frac {\partial w_{n-3}}{\partial x}}\right)\right)\\[6pt]&=\cdots \end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cb8633d881482245a77285d008ac3a902276c73c)
Compared to reverse accumulation, forward accumulation is natural and easy to implement as the flow of derivative information coincides with the order of evaluation. Each variable w is augmented with its derivative ẇ (stored as a numerical value, not a symbolic expression),

As an example, consider the function:

The choice of the independent variable to which differentiation is performed affects the seed values ẇ1 and ẇ2. Given interest in the derivative of this function with respect to x1, the seed values should be set to:

With the seed values set, the values propagate using the chain rule as shown. Figure 2 shows a pictorial depiction of this process as a computational graph.
Operations to compute value Operations to compute derivative (seed) (seed)










To compute the gradient of this example function, which requires the derivatives of f with respect to not only x1 but also x2, an additional sweep is performed over the computational graph using the seed values .

The computational complexity of one sweep of forward accumulation is proportional to the complexity of the original code.
Forward accumulation is more efficient than reverse accumulation for functions f : Rn → Rm with m ≫ n as only n sweeps are necessary, compared to m sweeps for reverse accumulation.
Reverse accumulation[]
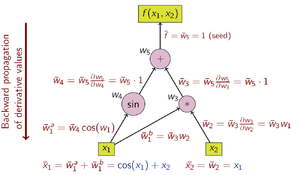
In reverse accumulation AD, the dependent variable to be differentiated is fixed and the derivative is computed with respect to each sub-expression recursively. In a pen-and-paper calculation, the derivative of the outer functions is repeatedly substituted in the chain rule:

In reverse accumulation, the quantity of interest is the adjoint, denoted with a bar (w̄); it is a derivative of a chosen dependent variable with respect to a subexpression w:

Reverse accumulation traverses the chain rule from outside to inside, or in the case of the computational graph in Figure 3, from top to bottom. The example function is scalar-valued, and thus there is only one seed for the derivative computation, and only one sweep of the computational graph is needed to calculate the (two-component) gradient. This is only half the work when compared to forward accumulation, but reverse accumulation requires the storage of the intermediate variables wi as well as the instructions that produced them in a data structure known as a Wengert list (or "tape"),[3][4] which may consume significant memory if the computational graph is large. This can be mitigated to some extent by storing only a subset of the intermediate variables and then reconstructing the necessary work variables by repeating the evaluations, a technique known as rematerialization. Checkpointing is also used to save intermediary states.
The operations to compute the derivative using reverse accumulation are shown in the table below (note the reversed order):
- Operations to compute derivative





The data flow graph of a computation can be manipulated to calculate the gradient of its original calculation. This is done by adding an adjoint node for each primal node, connected by adjoint edges which parallel the primal edges but flow in the opposite direction. The nodes in the adjoint graph represent multiplication by the derivatives of the functions calculated by the nodes in the primal. For instance, addition in the primal causes fanout in the adjoint; fanout in the primal causes addition in the adjoint;[a] a unary function y = f (x) in the primal causes x̄ = ȳ f ′(x) in the adjoint; etc.
Reverse accumulation is more efficient than forward accumulation for functions f : Rn → Rm with m ≪ n as only m sweeps are necessary, compared to n sweeps for forward accumulation.
Reverse mode AD was first published in 1976 by Seppo Linnainmaa.[5][6]
Backpropagation of errors in multilayer perceptrons, a technique used in machine learning, is a special case of reverse mode AD.[2]
Beyond forward and reverse accumulation[]
Forward and reverse accumulation are just two (extreme) ways of traversing the chain rule. The problem of computing a full Jacobian of f : Rn → Rm with a minimum number of arithmetic operations is known as the optimal Jacobian accumulation (OJA) problem, which is NP-complete.[7] Central to this proof is the idea that algebraic dependencies may exist between the local partials that label the edges of the graph. In particular, two or more edge labels may be recognized as equal. The complexity of the problem is still open if it is assumed that all edge labels are unique and algebraically independent.
Automatic differentiation using dual numbers[]
Forward mode automatic differentiation is accomplished by augmenting the algebra of real numbers and obtaining a new arithmetic. An additional component is added to every number to represent the derivative of a function at the number, and all arithmetic operators are extended for the augmented algebra. The augmented algebra is the algebra of dual numbers.
Replace every number with the number , where is a real number, but is an abstract number with the property (an infinitesimal; see Smooth infinitesimal analysis). Using only this, regular arithmetic gives






Now, polynomials can be calculated in this augmented arithmetic. If , then




The new arithmetic consists of ordered pairs, elements written , with ordinary arithmetics on the first component, and first order differentiation arithmetic on the second component, as described above. Extending the above results on polynomials to analytic functions gives a list of the basic arithmetic and some standard functions for the new arithmetic:






When a binary basic arithmetic operation is applied to mixed arguments—the pair and the real number —the real number is first lifted to . The derivative of a function at the point is now found by calculating using the above arithmetic, which gives as the result.







Vector arguments and functions[]
Multivariate functions can be handled with the same efficiency and mechanisms as univariate functions by adopting a directional derivative operator. That is, if it is sufficient to compute , the directional derivative of at in the direction , this may be calculated as using the same arithmetic as above. If all the elements of are desired, then function evaluations are required. Note that in many optimization applications, the directional derivative is indeed sufficient.








High order and many variables[]
The above arithmetic can be generalized to calculate second order and higher derivatives of multivariate functions. However, the arithmetic rules quickly grow complicated: complexity is quadratic in the highest derivative degree. Instead, truncated Taylor polynomial algebra can be used. The resulting arithmetic, defined on generalized dual numbers, allows efficient computation using functions as if they were a data type. Once the Taylor polynomial of a function is known, the derivatives are easily extracted.
Implementation[]
Forward-mode AD is implemented by a of the program in which real numbers are replaced by dual numbers, constants are lifted to dual numbers with a zero epsilon coefficient, and the numeric primitives are lifted to operate on dual numbers. This nonstandard interpretation is generally implemented using one of two strategies: source code transformation or operator overloading.
Source code transformation (SCT)[]
The source code for a function is replaced by an automatically generated source code that includes statements for calculating the derivatives interleaved with the original instructions.
Source code transformation can be implemented for all programming languages, and it is also easier for the compiler to do compile time optimizations. However, the implementation of the AD tool itself is more difficult.
Operator overloading (OO)[]

Operator overloading is a possibility for source code written in a language supporting it. Objects for real numbers and elementary mathematical operations must be overloaded to cater for the augmented arithmetic depicted above. This requires no change in the form or sequence of operations in the original source code for the function to be differentiated, but often requires changes in basic data types for numbers and vectors to support overloading and often also involves the insertion of special flagging operations.
Operator overloading for forward accumulation is easy to implement, and also possible for reverse accumulation. However, current compilers lag behind in optimizing the code when compared to forward accumulation.
Operator overloading, for both forward and reverse accumulation, can be well-suited to applications where the objects are vectors of real numbers rather than scalars. This is because the tape then comprises vector operations; this can facilitate computationally efficient implementations where each vector operation performs many scalar operations. Vector adjoint algorithmic differentiation (vector AAD) techniques may be used, for example, to differentiate values calculated by Monte-Carlo simulation.
Examples of operator-overloading implementations of automatic differentiation in C++ are the Adept and Stan libraries.
See also[]
Notes[]
![{\displaystyle [1\cdots 1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bf45494491a9127a08ac5f529d6c2e7fa9df6bd1)
![{\displaystyle [1\cdots 1]\left[{\begin{smallmatrix}x_{1}\\\vdots \\x_{n}\end{smallmatrix}}\right]=x_{1}+\cdots +x_{n},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7a9a62ad6b33394bb459d2a5fd08b3ed4394cfe6)
![{\displaystyle \left[{\begin{smallmatrix}1\\\vdots \\1\end{smallmatrix}}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d41449e0a185da184e5a72cfc317e2d99cbf6116)
![{\displaystyle \left[{\begin{smallmatrix}1\\\vdots \\1\end{smallmatrix}}\right][x]=\left[{\begin{smallmatrix}x\\\vdots \\x\end{smallmatrix}}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d33d5fcc124ef2bdffd63c5c21a8ac5de293d50c)
References[]
- ^ Neidinger, Richard D. (2010). "Introduction to Automatic Differentiation and MATLAB Object-Oriented Programming" (PDF). SIAM Review. 52 (3): 545–563. CiteSeerX 10.1.1.362.6580. doi:10.1137/080743627.
- ^ Jump up to: a b Baydin, Atilim Gunes; Pearlmutter, Barak; Radul, Alexey Andreyevich; Siskind, Jeffrey (2018). "Automatic differentiation in machine learning: a survey". Journal of Machine Learning Research. 18: 1–43.
- ^ R.E. Wengert (1964). "A simple automatic derivative evaluation program". Comm. ACM. 7 (8): 463–464. doi:10.1145/355586.364791.
- ^ Bartholomew-Biggs, Michael; Brown, Steven; Christianson, Bruce; Dixon, Laurence (2000). "Automatic differentiation of algorithms". Journal of Computational and Applied Mathematics. 124 (1–2): 171–190. Bibcode:2000JCoAM.124..171B. doi:10.1016/S0377-0427(00)00422-2. hdl:2299/3010.
- ^ Linnainmaa, Seppo (1976). "Taylor Expansion of the Accumulated Rounding Error". BIT Numerical Mathematics. 16 (2): 146–160. doi:10.1007/BF01931367.
- ^ Griewank, Andreas (2012). "Who Invented the Reverse Mode of Differentiation?" (PDF). Optimization Stories, Documenta Matematica. Extra Volume ISMP: 389–400.
- ^ Naumann, Uwe (April 2008). "Optimal Jacobian accumulation is NP-complete". Mathematical Programming. 112 (2): 427–441. CiteSeerX 10.1.1.320.5665. doi:10.1007/s10107-006-0042-z.
Further reading[]
- Rall, Louis B. (1981). Automatic Differentiation: Techniques and Applications. Lecture Notes in Computer Science. 120. Springer. ISBN 978-3-540-10861-0.
- Griewank, Andreas; Walther, Andrea (2008). Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation. Other Titles in Applied Mathematics. 105 (2nd ed.). SIAM. ISBN 978-0-89871-659-7. Archived from the original on 2010-03-23. Retrieved 2009-10-21.
- Neidinger, Richard (2010). "Introduction to Automatic Differentiation and MATLAB Object-Oriented Programming" (PDF). SIAM Review. 52 (3): 545–563. CiteSeerX 10.1.1.362.6580. doi:10.1137/080743627. Retrieved 2013-03-15.
- Naumann, Uwe (2012). The Art of Differentiating Computer Programs. Software-Environments-tools. SIAM. ISBN 978-1-611972-06-1.
- Henrard, Marc (2017). Algorithmic Differentiation in Finance Explained. Financial Engineering Explained. Palgrave Macmillan. ISBN 978-3-319-53978-2.
External links[]
- www.autodiff.org, An "entry site to everything you want to know about automatic differentiation"
- Automatic Differentiation of Parallel OpenMP Programs
- Automatic Differentiation, C++ Templates and Photogrammetry
- Automatic Differentiation, Operator Overloading Approach
- Compute analytic derivatives of any Fortran77, Fortran95, or C program through a web-based interface Automatic Differentiation of Fortran programs
- Description and example code for forward Automatic Differentiation in Scala
- finmath-lib automatic differentiation extensions, Automatic differentiation for random variables (Java implementation of the stochastic automatic differentiation).
- Adjoint Algorithmic Differentiation: Calibration and Implicit Function Theorem
- C++ Template-based automatic differentiation article and implementation
- Tangent Source-to-Source Debuggable Derivatives
- [1], Exact First- and Second-Order Greeks by Algorithmic Differentiation
- [2], Adjoint Algorithmic Differentiation of a GPU Accelerated Application
- [3], Adjoint Methods in Computational Finance Software Tool Support for Algorithmic Differentiationop
| show Differentiable computing |
|---|

| show Authority control |
|---|
- Differential calculus
- Computer algebra