Backpropagation
| Part of a series on |
| Machine learning and data mining |
|---|
 |
In machine learning, backpropagation (backprop,[1] BP) is a widely used algorithm for training feedforward neural networks. Generalizations of backpropagation exist for other artificial neural networks (ANNs), and for functions generally. These classes of algorithms are all referred to generically as "backpropagation".[2] In fitting a neural network, backpropagation computes the gradient of the loss function with respect to the weights of the network for a single input–output example, and does so efficiently, unlike a naive direct computation of the gradient with respect to each weight individually. This efficiency makes it feasible to use gradient methods for training multilayer networks, updating weights to minimize loss; gradient descent, or variants such as stochastic gradient descent, are commonly used. The backpropagation algorithm works by computing the gradient of the loss function with respect to each weight by the chain rule, computing the gradient one layer at a time, iterating backward from the last layer to avoid redundant calculations of intermediate terms in the chain rule; this is an example of dynamic programming.[3]
The term backpropagation strictly refers only to the algorithm for computing the gradient, not how the gradient is used; however, the term is often used loosely to refer to the entire learning algorithm, including how the gradient is used, such as by stochastic gradient descent.[4] Backpropagation generalizes the gradient computation in the delta rule, which is the single-layer version of backpropagation, and is in turn generalized by automatic differentiation, where backpropagation is a special case of reverse accumulation (or "reverse mode").[5] The term backpropagation and its general use in neural networks was announced in Rumelhart, Hinton & Williams (1986a), then elaborated and popularized in Rumelhart, Hinton & Williams (1986b), but the technique was independently rediscovered many times, and had many predecessors dating to the 1960s; see § History.[6] A modern overview is given in the deep learning textbook by Goodfellow, Bengio & Courville (2016).[7]
Overview[]
Backpropagation computes the gradient in weight space of a feedforward neural network, with respect to a loss function. Denote:
- : input (vector of features)
- : target output
- For classification, output will be a vector of class probabilities (e.g., , and target output is a specific class, encoded by the one-hot/dummy variable (e.g., ).
- : loss function or "cost function"[a]
- For classification, this is usually cross entropy (XC, log loss), while for regression it is usually squared error loss (SEL).
- : the number of layers
- : the weights between layer and , where is the weight between the -th node in layer and the -th node in layer [b]
- : activation functions at layer
- For classification the last layer is usually the logistic function for binary classification, and softmax (softargmax) for multi-class classification, while for the hidden layers this was traditionally a sigmoid function (logistic function or others) on each node (coordinate), but today is more varied, with rectifier (ramp, ReLU) being common.













In the derivation of backpropagation, other intermediate quantities are used; they are introduced as needed below. Bias terms are not treated specially, as they correspond to a weight with a fixed input of 1. For the purpose of backpropagation, the specific loss function and activation functions do not matter, as long as they and their derivatives can be evaluated efficiently.
The overall network is a combination of function composition and matrix multiplication:

For a training set there will be a set of input–output pairs, . For each input–output pair in the training set, the loss of the model on that pair is the cost of the difference between the predicted output and the target output :





Note the distinction: during model evaluation, the weights are fixed, while the inputs vary (and the target output may be unknown), and the network ends with the output layer (it does not include the loss function). During model training, the input–output pair is fixed, while the weights vary, and the network ends with the loss function.
Backpropagation computes the gradient for a fixed input–output pair , where the weights can vary. Each individual component of the gradient, can be computed by the chain rule; however, doing this separately for each weight is inefficient. Backpropagation efficiently computes the gradient by avoiding duplicate calculations and not computing unnecessary intermediate values, by computing the gradient of each layer – specifically, the gradient of the weighted input of each layer, denoted by – from back to front.


Informally, the key point is that since the only way a weight in affects the loss is through its effect on the next layer, and it does so linearly, are the only data you need to compute the gradients of the weights at layer , and then you can compute the previous layer and repeat recursively. This avoids inefficiency in two ways. Firstly, it avoids duplication because when computing the gradient at layer , you do not need to recompute all the derivatives on later layers each time. Secondly, it avoids unnecessary intermediate calculations because at each stage it directly computes the gradient of the weights with respect to the ultimate output (the loss), rather than unnecessarily computing the derivatives of the values of hidden layers with respect to changes in weights .




Backpropagation can be expressed for simple feedforward networks in terms of matrix multiplication, or more generally in terms of the adjoint graph.
Matrix multiplication[]
For the basic case of a feedforward network, where nodes in each layer are connected only to nodes in the immediate next layer (without skipping any layers), and there is a loss function that computes a scalar loss for the final output, backpropagation can be understood simply by matrix multiplication.[c] Essentially, backpropagation evaluates the expression for the derivative of the cost function as a product of derivatives between each layer from left to right – "backwards" – with the gradient of the weights between each layer being a simple modification of the partial products (the "backwards propagated error").
Given an input–output pair , the loss is:


To compute this, one starts with the input and works forward; denote the weighted input of each layer as and the output of layer as the activation . For backpropagation, the activation as well as the derivatives (evaluated at ) must be cached for use during the backwards pass.



The derivative of the loss in terms of the inputs is given by the chain rule; note that each term is a total derivative, evaluated at the value of the network (at each node) on the input :

These terms are: the derivative of the loss function;[d] the derivatives of the activation functions;[e] and the matrices of weights:[f]

The gradient is the transpose of the derivative of the output in terms of the input, so the matrices are transposed and the order of multiplication is reversed, but the entries are the same:


Backpropagation then consists essentially of evaluating this expression from right to left (equivalently, multiplying the previous expression for the derivative from left to right), computing the gradient at each layer on the way; there is an added step, because the gradient of the weights isn't just a subexpression: there's an extra multiplication.
Introducing the auxiliary quantity for the partial products (multiplying from right to left), interpreted as the "error at level " and defined as the gradient of the input values at level :

Note that is a vector, of length equal to the number of nodes in level ; each component is interpreted as the "cost attributable to (the value of) that node".
The gradient of the weights in layer is then:

The factor of is because the weights between level and affect level proportionally to the inputs (activations): the inputs are fixed, the weights vary.

The can easily be computed recursively as:

The gradients of the weights can thus be computed using a few matrix multiplications for each level; this is backpropagation.
Compared with naively computing forwards (using the for illustration):

there are two key differences with backpropagation:
- Computing in terms of avoids the obvious duplicate multiplication of layers and beyond.
- Multiplying starting from – propagating the error backwards – means that each step simply multiplies a vector () by the matrices of weights and derivatives of activations . By contrast, multiplying forwards, starting from the changes at an earlier layer, means that each multiplication multiplies a matrix by a matrix. This is much more expensive, and corresponds to tracking every possible path of a change in one layer forward to changes in the layer (for multiplying by , with additional multiplications for the derivatives of the activations), which unnecessarily computes the intermediate quantities of how weight changes affect the values of hidden nodes.






Adjoint graph[]
This section needs expansion. You can help by . (November 2019) |
For more general graphs, and other advanced variations, backpropagation can be understood in terms of automatic differentiation, where backpropagation is a special case of reverse accumulation (or "reverse mode").[5]
Intuition[]
Motivation[]
The goal of any supervised learning algorithm is to find a function that best maps a set of inputs to their correct output. The motivation for backpropagation is to train a multi-layered neural network such that it can learn the appropriate internal representations to allow it to learn any arbitrary mapping of input to output.[8]
Learning as an optimization problem[]
To understand the mathematical derivation of the backpropagation algorithm, it helps to first develop some intuition about the relationship between the actual output of a neuron and the correct output for a particular training example. Consider a simple neural network with two input units, one output unit and no hidden units, and in which each neuron uses a linear output (unlike most work on neural networks, in which mapping from inputs to outputs is non-linear)[g] that is the weighted sum of its input.

Initially, before training, the weights will be set randomly. Then the neuron learns from training examples, which in this case consist of a set of tuples where and are the inputs to the network and t is the correct output (the output the network should produce given those inputs, when it has been trained). The initial network, given and , will compute an output y that likely differs from t (given random weights). A loss function is used for measuring the discrepancy between the target output t and the computed output y. For regression analysis problems the squared error can be used as a loss function, for classification the categorical crossentropy can be used.




As an example consider a regression problem using the square error as a loss:

where E is the discrepancy or error.
Consider the network on a single training case: . Thus, the input and are 1 and 1 respectively and the correct output, t is 0. Now if the relation is plotted between the network's output y on the horizontal axis and the error E on the vertical axis, the result is a parabola. The minimum of the parabola corresponds to the output y which minimizes the error E. For a single training case, the minimum also touches the horizontal axis, which means the error will be zero and the network can produce an output y that exactly matches the target output t. Therefore, the problem of mapping inputs to outputs can be reduced to an optimization problem of finding a function that will produce the minimal error.


However, the output of a neuron depends on the weighted sum of all its inputs:

where and are the weights on the connection from the input units to the output unit. Therefore, the error also depends on the incoming weights to the neuron, which is ultimately what needs to be changed in the network to enable learning.


In this example, upon injecting the training data the loss function becomes

Then, the loss function takes the form of a parabolic cylinder with its base directed along . Since all sets of weights that satisfy minimize the loss function, in this case additional constraints are required to converge to a unique solution. Additional constraints could either be generated by setting specific conditions to the weights, or by injecting additional training data.


One commonly used algorithm to find the set of weights that minimizes the error is gradient descent. By backpropagation, the steepest descent direction is calculated of the loss function versus the present synaptic weights. Then, the weights can be modified along the steepest descent direction, and the error is minimized in an efficient way.
Derivation[]
The gradient descent method involves calculating the derivative of the loss function with respect to the weights of the network. This is normally done using backpropagation. Assuming one output neuron,[h] the squared error function is

where
- is the loss for the output and target value ,
- is the target output for a training sample, and
- is the actual output of the output neuron.

For each neuron , its output is defined as


where the activation function is non-linear and differentiable (even if the ReLU is not in one point). A historically used activation function is the logistic function:


which has a convenient derivative of:

The input to a neuron is the weighted sum of outputs of previous neurons. If the neuron is in the first layer after the input layer, the of the input layer are simply the inputs to the network. The number of input units to the neuron is . The variable denotes the weight between neuron of the previous layer and neuron of the current layer.





Finding the derivative of the error[]
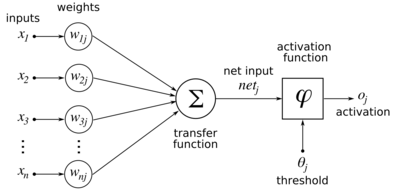
Calculating the partial derivative of the error with respect to a weight is done using the chain rule twice:

-
(Eq. 1)

In the last factor of the right-hand side of the above, only one term in the sum depends on , so that
-
(Eq. 2)

If the neuron is in the first layer after the input layer, is just .


The derivative of the output of neuron with respect to its input is simply the partial derivative of the activation function:
-
(Eq. 3)

which for the logistic activation function case is:

This is the reason why backpropagation requires the activation function to be differentiable. (Nevertheless, the ReLU activation function, which is non-differentiable at 0, has become quite popular, e.g. in AlexNet)
The first factor is straightforward to evaluate if the neuron is in the output layer, because then and

-
(Eq. 4)

If half of the square error is used as loss function we can rewrite it as

However, if is in an arbitrary inner layer of the network, finding the derivative with respect to is less obvious.
Considering as a function with the inputs being all neurons receiving input from neuron ,


and taking the total derivative with respect to , a recursive expression for the derivative is obtained:
-
(Eq. 5)

Therefore, the derivative with respect to can be calculated if all the derivatives with respect to the outputs of the next layer – the ones closer to the output neuron – are known. [Note, if any of the neurons in set were not connected to neuron , they would be independent of and the corresponding partial derivative under the summation would vanish to 0.]

Substituting Eq. 2, Eq. 3 Eq.4 and Eq. 5 in Eq. 1 we obtain:


with

if is the logistic function, and the error is the square error:

To update the weight using gradient descent, one must choose a learning rate, . The change in weight needs to reflect the impact on of an increase or decrease in . If , an increase in increases ; conversely, if , an increase in decreases . The new is added to the old weight, and the product of the learning rate and the gradient, multiplied by guarantees that changes in a way that always decreases . In other words, in the equation immediately below, always changes in such a way that is decreased:







Loss function[]
The loss function is a function that maps values of one or more variables onto a real number intuitively representing some "cost" associated with those values. For backpropagation, the loss function calculates the difference between the network output and its expected output, after a training example has propagated through the network.
Assumptions[]
The mathematical expression of the loss function must fulfill two conditions in order for it to be possibly used in backpropagation.[9] The first is that it can be written as an average over error functions , for individual training examples, . The reason for this assumption is that the backpropagation algorithm calculates the gradient of the error function for a single training example, which needs to be generalized to the overall error function. The second assumption is that it can be written as a function of the outputs from the neural network.




Example loss function[]
Let be vectors in .


Select an error function measuring the difference between two outputs. The standard choice is the square of the Euclidean distance between the vectors and :




Limitations[]

- Gradient descent with backpropagation is not guaranteed to find the global minimum of the error function, but only a local minimum; also, it has trouble crossing plateaus in the error function landscape. This issue, caused by the non-convexity of error functions in neural networks, was long thought to be a major drawback, but Yann LeCun et al. argue that in many practical problems, it is not.[10]
- Backpropagation learning does not require normalization of input vectors; however, normalization could improve performance.[11]
- Backpropagation requires the derivatives of activation functions to be known at network design time.
History[]
The term backpropagation and its general use in neural networks was announced in Rumelhart, Hinton & Williams (1986a), then elaborated and popularized in Rumelhart, Hinton & Williams (1986b), but the technique was independently rediscovered many times, and had many predecessors dating to the 1960s.[6][12]
The basics of continuous backpropagation were derived in the context of control theory by Henry J. Kelley in 1960,[13] and by Arthur E. Bryson in 1961.[14][15][16][17][18] They used principles of dynamic programming. In 1962, Stuart Dreyfus published a simpler derivation based only on the chain rule.[19] Bryson and Ho described it as a multi-stage dynamic system optimization method in 1969.[20][21] Backpropagation was derived by multiple researchers in the early 60's[17] and implemented to run on computers as early as 1970 by Seppo Linnainmaa.[22][23][24] Paul Werbos was first in the US to propose that it could be used for neural nets after analyzing it in depth in his 1974 dissertation.[25] While not applied to neural networks, in 1970 Linnainmaa published the general method for automatic differentiation (AD).[23][24] Although very controversial, some scientists believe this was actually the first step toward developing a back-propagation algorithm.[17][18][22][26] In 1973 Dreyfus adapts parameters of controllers in proportion to error gradients.[27] In 1974 Werbos mentioned the possibility of applying this principle to artificial neural networks,[25] and in 1982 he applied Linnainmaa's AD method to non-linear functions.[18][28]
Later the Werbos method was rediscovered and described in 1985 by Parker,[29][30] and in 1986 by Rumelhart, Hinton and Williams.[12][30][31] Rumelhart, Hinton and Williams showed experimentally that this method can generate useful internal representations of incoming data in hidden layers of neural networks.[8][32][33] Yann LeCun proposed the modern form of the back-propagation learning algorithm for neural networks in his PhD thesis in 1987. In 1993, Eric Wan won an international pattern recognition contest through backpropagation.[17][34]
During the 2000s it fell out of favour, but returned in the 2010s, benefitting from cheap, powerful GPU-based computing systems. This has been especially so in speech recognition, machine vision, natural language processing, and language structure learning research (in which it has been used to explain a variety of phenomena related to first[35] and second language learning.[36]).
Error backpropagation has been suggested to explain human brain ERP components like the N400 and P600.[37]
See also[]
- Artificial neural network
- Biological neural network
- Catastrophic interference
- Ensemble learning
- AdaBoost
- Overfitting
- Neural backpropagation
- Backpropagation through time
Notes[]
- ^ Use for the loss function to allow to be used for the number of layers
- ^ This follows Nielsen (2015), and means (left) multiplication by the matrix corresponds to converting output values of layer to input values of layer : columns correspond to input coordinates, rows correspond to output coordinates.
- ^ This section largely follows and summarizes Nielsen (2015).
- ^ The derivative of the loss function is a covector, since the loss function is a scalar-valued function of several variables.
- ^ The activation function is applied to each node separately, so the derivative is just the diagonal matrix of the derivative on each node. This is often represented as the Hadamard product with the vector of derivatives, denoted by , which is mathematically identical but better matches the internal representation of the derivatives as a vector, rather than a diagonal matrix.
- ^ Since matrix multiplication is linear, the derivative of multiplying by a matrix is just the matrix: .
- ^ One may notice that multi-layer neural networks use non-linear activation functions, so an example with linear neurons seems obscure. However, even though the error surface of multi-layer networks are much more complicated, locally they can be approximated by a paraboloid. Therefore, linear neurons are used for simplicity and easier understanding.
- ^ There can be multiple output neurons, in which case the error is the squared norm of the difference vector.


References[]
- ^ Goodfellow, Bengio & Courville 2016, p. 200, "The back-propagation algorithm (Rumelhart et al., 1986a), often simply called backprop, ..."
- ^ Goodfellow, Bengio & Courville 2016, p. 200, "Furthermore, back-propagation is often misunderstood as being specific to multi-layer neural networks, but in principle it can compute derivatives of any function"
- ^ Goodfellow, Bengio & Courville 2016, p. 214, "This table-filling strategy is sometimes called dynamic programming."
- ^ Goodfellow, Bengio & Courville 2016, p. 200, "The term back-propagation is often misunderstood as meaning the whole learning algorithm for multilayer neural networks. Backpropagation refers only to the method for computing the gradient, while other algorithms, such as stochastic gradient descent, is used to perform learning using this gradient."
- ^ Jump up to: a b Goodfellow, Bengio & Courville (2016, p. 217–218), "The back-propagation algorithm described here is only one approach to automatic differentiation. It is a special case of a broader class of techniques called reverse mode accumulation."
- ^ Jump up to: a b Goodfellow, Bengio & Courville (2016, p. 221), "Efficient applications of the chain rule based on dynamic programming began to appear in the 1960s and 1970s, mostly for control applications (Kelley, 1960; Bryson and Denham, 1961; Dreyfus, 1962; Bryson and Ho, 1969; Dreyfus, 1973) but also for sensitivity analysis (Linnainmaa, 1976). ... The idea was finally developed in practice after being independently rediscovered in different ways (LeCun, 1985; Parker, 1985; Rumelhart et al., 1986a). The book Parallel Distributed Processing presented the results of some of the first successful experiments with back-propagation in a chapter (Rumelhart et al., 1986b) that contributed greatly to the popularization of back-propagation and initiated a very active period of research in multilayer neural networks."
- ^ Goodfellow, Bengio & Courville (2016, 6.5 Back-Propagation and Other Differentiation Algorithms, pp. 200–220)
- ^ Jump up to: a b Rumelhart, David E.; Hinton, Geoffrey E.; Williams, Ronald J. (1986a). "Learning representations by back-propagating errors". Nature. 323 (6088): 533–536. Bibcode:1986Natur.323..533R. doi:10.1038/323533a0. S2CID 205001834.
- ^ Nielsen (2015), "[W]hat assumptions do we need to make about our cost function ... in order that backpropagation can be applied? The first assumption we need is that the cost function can be written as an average ... over cost functions ... for individual training examples ... The second assumption we make about the cost is that it can be written as a function of the outputs from the neural network ..."
- ^ LeCun, Yann; Bengio, Yoshua; Hinton, Geoffrey (2015). "Deep learning". Nature. 521 (7553): 436–444. Bibcode:2015Natur.521..436L. doi:10.1038/nature14539. PMID 26017442. S2CID 3074096.
- ^ Buckland, Matt; Collins, Mark (2002). AI Techniques for Game Programming. Boston: Premier Press. ISBN 1-931841-08-X.
- ^ Jump up to: a b Rumelhart; Hinton; Williams (1986). "Learning representations by back-propagating errors" (PDF). Nature. 323 (6088): 533–536. Bibcode:1986Natur.323..533R. doi:10.1038/323533a0. S2CID 205001834.
- ^ Kelley, Henry J. (1960). "Gradient theory of optimal flight paths". ARS Journal. 30 (10): 947–954. doi:10.2514/8.5282.
- ^ Bryson, Arthur E. (1962). "A gradient method for optimizing multi-stage allocation processes". Proceedings of the Harvard Univ. Symposium on digital computers and their applications, 3–6 April 1961. Cambridge: Harvard University Press. OCLC 498866871.
- ^ Dreyfus, Stuart E. (1990). "Artificial Neural Networks, Back Propagation, and the Kelley-Bryson Gradient Procedure". Journal of Guidance, Control, and Dynamics. 13 (5): 926–928. Bibcode:1990JGCD...13..926D. doi:10.2514/3.25422.
- ^ Mizutani, Eiji; Dreyfus, Stuart; Nishio, Kenichi (July 2000). "On derivation of MLP backpropagation from the Kelley-Bryson optimal-control gradient formula and its application" (PDF). Proceedings of the IEEE International Joint Conference on Neural Networks.
- ^ Jump up to: a b c d Schmidhuber, Jürgen (2015). "Deep learning in neural networks: An overview". Neural Networks. 61: 85–117. arXiv:1404.7828. doi:10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509.
- ^ Jump up to: a b c Schmidhuber, Jürgen (2015). "Deep Learning". Scholarpedia. 10 (11): 32832. Bibcode:2015SchpJ..1032832S. doi:10.4249/scholarpedia.32832.
- ^ Dreyfus, Stuart (1962). "The numerical solution of variational problems". Journal of Mathematical Analysis and Applications. 5 (1): 30–45. doi:10.1016/0022-247x(62)90004-5.
- ^ Russell, Stuart; Norvig, Peter (1995). Artificial Intelligence : A Modern Approach. Englewood Cliffs: Prentice Hall. p. 578. ISBN 0-13-103805-2.
The most popular method for learning in multilayer networks is called Back-propagation. It was first invented in 1969 by Bryson and Ho, but was more or less ignored until the mid-1980s.
- ^ Bryson, Arthur Earl; Ho, Yu-Chi (1969). Applied optimal control: optimization, estimation, and control. Waltham: Blaisdell. OCLC 3801.
- ^ Jump up to: a b Griewank, Andreas (2012). "Who Invented the Reverse Mode of Differentiation?". Optimization Stories. Documenta Matematica, Extra Volume ISMP. pp. 389–400. S2CID 15568746.
- ^ Jump up to: a b Seppo Linnainmaa (1970). The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's Thesis (in Finnish), Univ. Helsinki, 6–7.
- ^ Jump up to: a b Linnainmaa, Seppo (1976). "Taylor expansion of the accumulated rounding error". BIT Numerical Mathematics. 16 (2): 146–160. doi:10.1007/bf01931367. S2CID 122357351.
- ^ Jump up to: a b The thesis, and some supplementary information, can be found in his book, Werbos, Paul J. (1994). The Roots of Backpropagation : From Ordered Derivatives to Neural Networks and Political Forecasting. New York: John Wiley & Sons. ISBN 0-471-59897-6.
- ^ Griewank, Andreas; Walther, Andrea (2008). Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation, Second Edition. SIAM. ISBN 978-0-89871-776-1.
- ^ Dreyfus, Stuart (1973). "The computational solution of optimal control problems with time lag". IEEE Transactions on Automatic Control. 18 (4): 383–385. doi:10.1109/tac.1973.1100330.
- ^ Werbos, Paul (1982). "Applications of advances in nonlinear sensitivity analysis" (PDF). System modeling and optimization. Springer. pp. 762–770.
- ^ Parker, D.B. (1985). "Learning Logic". Center for Computational Research in Economics and Management Science. Cambridge MA: Massachusetts Institute of Technology. Cite journal requires
|journal=(help) - ^ Jump up to: a b Hertz, John. (1991). Introduction to the theory of neural computation. Krogh, Anders., Palmer, Richard G. Redwood City, Calif.: Addison-Wesley Pub. Co. p. 8. ISBN 0-201-50395-6. OCLC 21522159.
- ^ Anderson, James Arthur, (1939- ...)., ed. Rosenfeld, Edward, ed. (1988). Neurocomputing Foundations of research. MIT Press. ISBN 0-262-01097-6. OCLC 489622044.CS1 maint: multiple names: authors list (link) CS1 maint: extra text: authors list (link)
- ^ Rumelhart, David E.; Hinton, Geoffrey E.; Williams, Ronald J. (1986b). "8. Learning Internal Representations by Error Propagation". In Rumelhart, David E.; McClelland, James L. (eds.). Parallel Distributed Processing : Explorations in the Microstructure of Cognition. Volume 1 : Foundations. Cambridge: MIT Press. ISBN 0-262-18120-7.
|volume=has extra text (help) - ^ Alpaydin, Ethem (2010). Introduction to Machine Learning. MIT Press. ISBN 978-0-262-01243-0.
- ^ Wan, Eric A. (1994). "Time Series Prediction by Using a Connectionist Network with Internal Delay Lines". In Weigend, Andreas S.; Gershenfeld, Neil A. (eds.). Time Series Prediction : Forecasting the Future and Understanding the Past. Proceedings of the NATO Advanced Research Workshop on Comparative Time Series Analysis. Volume 15. Reading: Addison-Wesley. pp. 195–217. ISBN 0-201-62601-2. S2CID 12652643.
|volume=has extra text (help) - ^ Chang, Franklin; Dell, Gary S.; Bock, Kathryn (2006). "Becoming syntactic". Psychological Review. 113 (2): 234–272. doi:10.1037/0033-295x.113.2.234. PMID 16637761.
- ^ Janciauskas, Marius; Chang, Franklin (2018). "Input and Age-Dependent Variation in Second Language Learning: A Connectionist Account". Cognitive Science. 42: 519–554. doi:10.1111/cogs.12519. PMC 6001481. PMID 28744901.
- ^ Fitz, Hartmut; Chang, Franklin (2019). "Language ERPs reflect learning through prediction error propagation". Cognitive Psychology. 111: 15–52. doi:10.1016/j.cogpsych.2019.03.002. hdl:21.11116/0000-0003-474D-8. PMID 30921626. S2CID 85501792.
Further reading[]
- Goodfellow, Ian; Bengio, Yoshua; Courville, Aaron (2016). "6.5 Back-Propagation and Other Differentiation Algorithms". Deep Learning. MIT Press. pp. 200–220. ISBN 9780262035613.
- Nielsen, Michael A. (2015). "How the backpropagation algorithm works". Neural Networks and Deep Learning. Determination Press.
- McCaffrey, James (October 2012). "Neural Network Back-Propagation for Programmers". MSDN Magazine.
- Rojas, Raúl (1996). "The Backpropagation Algorithm" (PDF). Neural Networks : A Systematic Introduction. Berlin: Springer. ISBN 3-540-60505-3.
External links[]
- Backpropagation neural network tutorial at the Wikiversity
- Bernacki, Mariusz; Włodarczyk, Przemysław (2004). "Principles of training multi-layer neural network using backpropagation".
- Karpathy, Andrej (2016). "Lecture 4: Backpropagation, Neural Networks 1". CS231n. Stanford University – via YouTube.
- "What is Backpropagation Really Doing?". 3Blue1Brown. November 3, 2017 – via YouTube.
| show Differentiable computing |
|---|

| show Authority control |
|---|
- Machine learning algorithms
- Artificial neural networks